Entrepreneurial Geekiness
Entrepreneurial Geekiness
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products. More about Ian here.
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products.


Coaching

Training

Jobs

Products

Consulting
PyDataLondon 2017 Conference Call for Proposals Now Open
This year we’ll hold our 4th PyDataLondon conference during May 5th-7th at Bloomberg (thanks Bloomberg!). Our Call for Proposals is open and will run during February (closing date to be confirmed so don’t just forget about it! – get on with making a draft submission soon).
We want talks at all levels (first timers especially welcome) from beginner to advanced, we want both regular talks and tutorials. We’ll be experimenting with the overflow room just as we did last year (possibly including Office Hours and ‘how to contribute to open source’ workshops).
Take a look at the 2016 Schedule to see the range of talks we had – engineering, machine learning, deep learning, visualisation, medical, finance, NLP, Big Data – all the usual suspects. We want all of these and more.
Personally I’m especially interested in:
- talks that cover the communication of complex data (think – bad Daily Mail Brexit graphics and how we might help people communicate complex ideas more clearly)
- encouraging collaborations between sub-groups.
- building on last year’s medical track with more medical topics
- getting journalists involved and sharing their challenges and triumphs
- and I’d love to be surprised – if you think it’ll fit – put in a submission!
The process of submitting is very easy:
- Go to the website and sign-up to make an account (you’ll need a new one even if you submitted last year)
- Post a first-draft title and abstract (just a one-liner will do if you’re pressed for time)
- Give it a day, log back in and iterate to expand on this
- If your submission is too short then the Review Committee will tell you that you don’t meet the minimum criteria, so you’ll get nagged – but only if you’ve made an attempt first!
- Iterate, integrating feedback from the Committee, to improve your proposal
- Keep your fingers crossed that you get selected
We’re also accepting Sponsorship requests, take a look on the main site and get in contact. We’ve already closed some of the options so if you’d like the price list – get in contact via the website right away.
I’d like to extend a Thank You to the new and larger Review Committee. I’ve handed over the reigns on this, many thanks to the new committee for their efforts.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Practical ML for Engineers talk at #pyconuk last weekend
Last weekend I had the pleasure of introducing Machine Learning for Engineers (a practical walk-through, no maths) [YouTube video] at PyConUK 2016. Each year the conference grows and maintains a lovely vibe, this year it was up to 600 people! My talk covered a practical guide to a 2 class classification challenge (Kaggle’s Titanic) with scikit-learn, backed by a longer Jupyter Notebook (github) and further backed by Ezzeri’s 2 hour tutorial from PyConUK 2014.
Topics covered include:
- Going from raw data to a DataFrame (notable tip – read Katharine’s book on Data Wrangling)
- Starting with a DummyClassifier to get a baseline result (everything you do from here should give a better classification score than this!)
- Switching to a RandomForestClassifier, adding Features
- Switching from a train/test set to a cross validation methodology
- Dealing with NaN values using a sentinel value (robust for RandomForests, doesn’t require scaling, doesn’t require you to impute your own creative values)
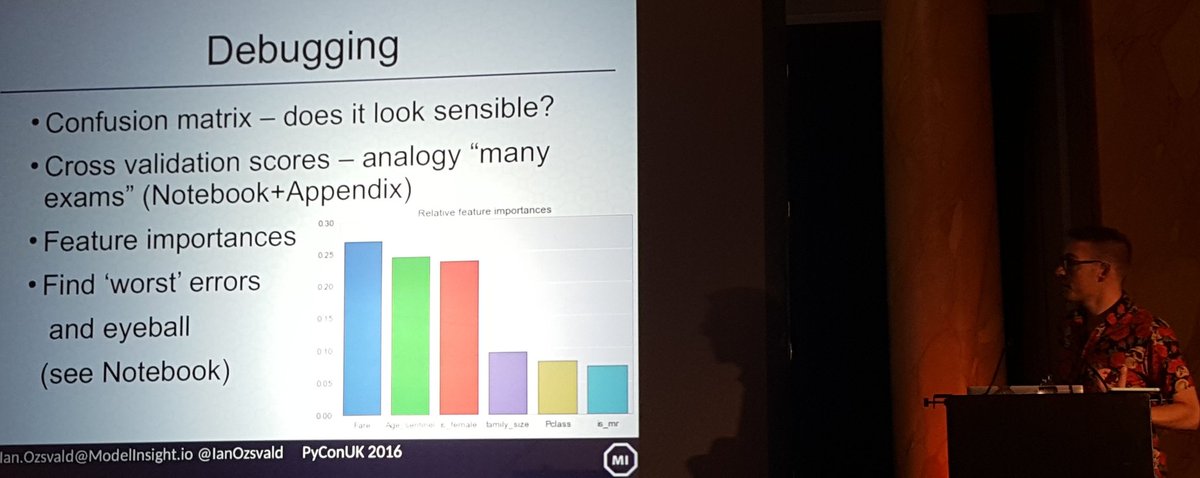
- Diagnosing quality and mistakes using a Confusion Matrix and looking at very-wrong classifications to give you insight back to the raw feature data
- Notes on deployment
I had to cover the above in 20 minutes, obviously that was a bit of a push! I plan to cover this talk again at regional meetups, probably with 30-40 minutes. As it stands the talk (github) should lead you into the Notebook and that’ll lead you to Ezzeri’s 2 hour tutorial. This should be enough to help you start on your own 2 class classification challenge, if your data looks ‘somewhat like’ the Titanic data.
I’m generally interested in the idea of helping more engineers get into data science and machine learning. If you’re curious – I have a longer set of notes called Data Science Delivered and some vague plans to maybe write a book (maybe) – for the book join the mailing list here if you’d like to hear more (no hard sell, almost no emails at the moment, I’m still figuring out if I should do this).
You might also want to follow-up on Katharine Jarmul’s data wrangling talk and tutorial, Nick Radcliffe’s Test Driven Data Analysis (with new automated TDD-for-data tool to come in a few months), Tim Vivian-Griffiths’ SVM Diagnostics, Dr. Gusztav Belteki’s Ventilator medical talk, Geoff French’s Deep Learning tutorial and Marco Bonzanini and Miguel ‘s Intro to ML tutorial. The videos are probably in this list.
If you like the above then do think on coming to our monthly PyDataLondon data science meetups near London Bridge.
PyConUK itself has grown amazingly – the core team put in a huge amount of effort. It was very cool to see the growth of the kids sessions, the trans track, all the tutorials and the general growth in the diversity of our community’s membership. I was quite sad to leave at lunch on the Sunday – next year I plan to stay longer, this community deserves more investment. If you’ve yet to attend a PyConUK then I strongly urge you to think on submitting a talk for next year and definitely suggest that you attend.
The organisers were kind enough to let Kat and myself do a book signing, I suggest other authors think on joining us next year. Attendees love meeting authors and it is yet another activity that helps bind the community together.

Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Some notes on building a conda recipe
I’ve spent the day building a conda recipe, the process wasn’t super-smooth, hopefully these notes will help others and/or maybe you can leave me a comment to improve my flow. The goal was to learn how to use conda to distribute a package that ordinarily I’d put on PyPI.
I’m using Linux 64bit (Mint 18 on an XPS 9550), conda 4.1 and conda build 1.21.14 (up to date as of today). My goal was to build a recipe (python_template_with_config_recipe) to install my python_template_with_config (a bit of boilerplate code I use sometimes when making a new project). That template has two modules, a test, a setup.py and it depends on numpy.
The short story:
- git clone https://github.com/ianozsvald/python_template_with_config_recipe.git
- cd inside, run “conda build –debug .”
- # note the period means “current directory” and that’s two dashes debug
- a local bzip will be built and you’ll see that the 1 test ran ok
On my machine the built code ends up in “~/anaconda3/pkgs/python_template_with_config-0.1-py35_0/lib/python3.5/site-packages/python_template_with_config” and the building takes place in “~/anaconda3/conda-bld/linux-64”.
In a new conda environment I can use “conda install –use-local python_template_with_config” and it’ll install the built recipe into the new environment.
To get started with this I first made a fresh empty conda environment (note that anaconda isn’t my default Python, hence the long-form access to `conda`):
-
$ ~/anaconda3/bin/conda create -n new_recipe_env python=3.5
-
$ . ~/anaconda3/bin/activate new_recipe_env
To check that my existing “setup.py” runs I use pip to install from git, we’ll need the setup.py in the conda recipe later so we want to confirm that it works:
-
$ pip install git+https://github.com/ianozsvald/python_template_with_config.git # runs setup.py
-
# $ pip uninstall python_template_with_config # use this if you need to uninstall whilst developing
I can check that this has installed as a module using:
In [1]: from python_template_with_config import another_module In [2]: another_module.a_math_function() # silly function just to check that numpy is installed Out[2]: -2.4492935982947064e-16
Now I’ll make a second conda environment to develop the recipe:
-
$ ~/anaconda3/bin/conda create -n new_recipe_env2 python=3.5 # vanilla environment, no numpy
-
$ . ~/anaconda3/bin/activate new_recipe_env2
-
git clone https://github.com/ianozsvald/python_template_with_config_recipe.git
-
cd inside, run "conda build --debug ."
The recipe (meta.yaml) will look at the git repo for python_template_with_config, pull down a copy, build using build.sh and the store a bzip2 archive locally. The build step also notes that I can upload this to Anaconda using `$ anaconda upload /home/ian/anaconda3/conda-bld/linux-64/python_template_with_config-0.1-py35_0.tar.bz2`.
A few caveats occurred whilst creating the recipe:
- You need a bld.bat, build.sh, meta.yaml, at first I created bld.sh and meta.yml (both typos) and there were no complaints…just frustration on my part – the first clue was seeing “source tree in: /home/ian/anaconda3/conda-bld/work \n number of files: 0” in the build output
- When running conda build it seems to not overwrite the version in ~/anaconda3/pkgs/ – I ended up deleting “python_template_with_config-0.1-py35_0/” and “python_template_with_config-0.1-py35_0.tar.bz2” by hand just to make sure on each build iteration – I must be missing something here, please enlighten me (see note from Marco below)
- Having deleted the cached versions and fixed the typos I’d later see “number of files: 14”
- Later I added “run_tests.py” rather than “run_test.py”, I knew it wasn’t running as I’d added a “1/0” line inside run_tests.py that obviously wasn’t running (it should raise a ZeroDivisionError even if the tests did run ok). Again this was a typo on my part
- The above is tested on Linux, it ought to work on Windows but I’ve not tested it
- This meta.yaml installs from github, there’s a commented out line in there showing how to access the local source files instead
Marco Bonzanini has noted that “conda clean“, “conda clean -t” (tarballs) and “conda clean -p” (packages) can help with the caching issue mentioned above. He also notes “conda skeleton <pypi package url>” takes care of the boilerplate if you have a published version on PyPI, so that avoids the silly mistakes I made by hand. Cheers!
I didn’t get as far as uploading this to Anaconda to make it ‘public’ (as I don’t think that’s so useful) but I believe that final step is easy enough.
Useful docs:
- conda recipe tutorial
- meta.yaml specification
- Notes on laying out a Python package (as a precursor to making a setup.py file)
- In my recipe in github I’ve added a set of useful links in the meta.yaml and run_tests.py
- conda-forge and conda-recipes have lots more examples
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Results for “Which version of Python (2.x vs 3.x) do London Data Scientists use?”
Over the last week I’ve surveyed my PyDataLondon meetup community (3,400+ members) to ask “Which version of Python do you use at work and at home?”. The goal is to gain evidence about which versions of Python are used by Data Scientists. This will help tool developers so they can make evidence-based decisions (e.g. this Dask discussion and another for h5py) about which versions of Python need support now and in the future.
Below I also discuss some business risks of sticking with Python 2.7. Of 3,400+ members over 466 (13%) responded to the 4 emails I sent. By 2020 (3.5 years from now) Python 2.7’s support will end.
TL;DR Python 2.7 is still dominant for UK Data Scientists at work, Python 3.4 dominates outside of work, I hypothesise that 50% of London Data Scientists will be using Python 3.x by June 2017, business risks exist for companies who lack a 2.7->3.x migration plan.
Survey results:
At work Python 2.7 dominates (58%) for PyDataLondon members. Python 3.4+ is used by 33% of our respondents (including me).
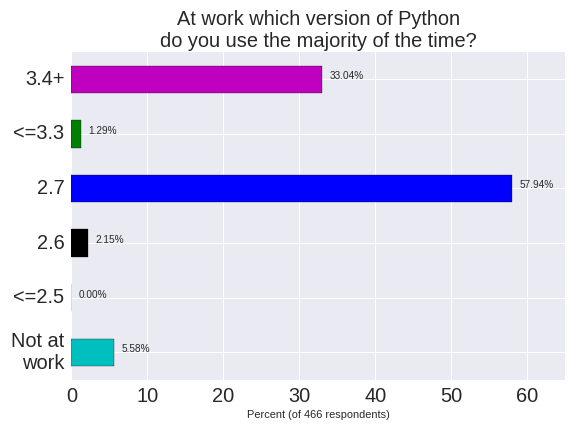
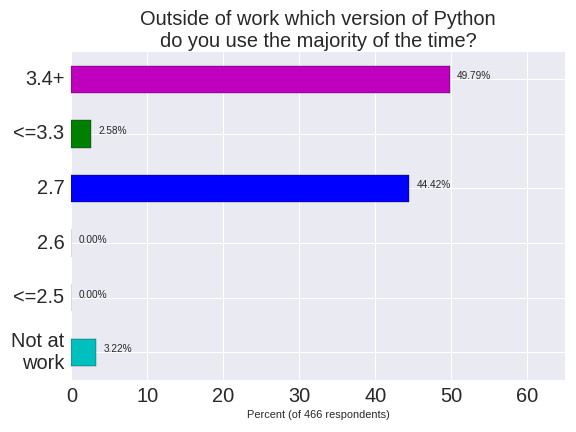
Outside of work Python 3.4+ dominates 2.7 by a small margin (the majority of home users choose Python 3.5 (37%) over 3.4 (12%)). For work and home usage Python versions <=3.3 and 2.6 are used by approximately 2% of respondents each, nobody uses <= 2.5. Separately I know at least 2 members at our meetups who have noted that they use Python 2.4 (so that’s at least 2 in 3,400 members).
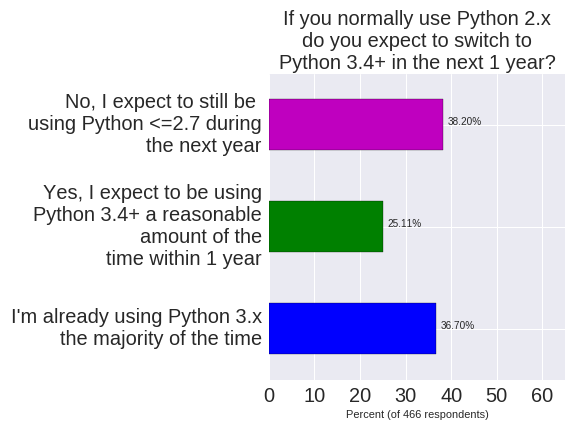
The more interesting outcome is “If you use Python 2.7 – do you expect to be using Python 3.x within a year?”. 25% of respondents are using Python 2.7 and do expect to upgrade. 36% are already on Python 3.x. 38% expect to still be using Python 2.7 in a year. Of the aspirational 25% who believe they’ll upgrade, I suspect that at least half of these will have upgraded within a year.
Hypothesis – if I survey again in June 2017 we’ll see Python 3.x usage at 50% of the PyDataLondon community.
When asked about a choice of distribution it is clear that Continuum’s Anaconda is the clear choice. A significant number of users still use their Operating System’s default Python.
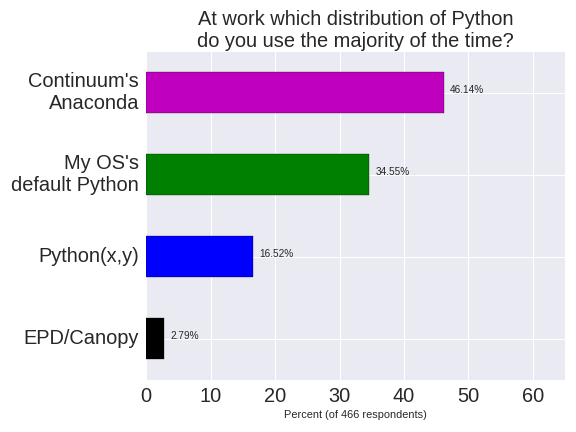
Edit – I did have a question about choice of Operating System but I’d left it as a multiple-choice not single choice question. Since the results were hard to interpret I’ve removed that result.
The above results mirror the finding in Randal Olson’s recent 2014 and 2013 surveys. There are a couple of related (early 2015 for scientific Python users) surveys (2013).
There’s a final question on “Anything else you’d like to add?”. Some users note that they are fixed to 2.7 for the time being due to a large legacy code-base. This sort of theme “Current python use at work is around 60% 2.7 and 40% 3.4 .. this ratio is continuously moving towards 3.4 as most new things are in 3.4+.” and “Just made jump to Py3, still have a body of legacy running under 2” occurred through-out the comments. Nobody commented that they’d moved backwards and nobody ruled-out upgrading (though some said that they were in no hurry).
Business risk: A few newer tools are only written for Python 3.4+ and are unlikely to be back-ported. Some established projects (e.g. IPython/Jupyter) are moving their next development versions to Python 3.4+ and keeping Python 2.7 for the current branch as a move towards discontinuing Python 2.7 support. There’s an increasing risk that Python 2.7-based Data Scientists will see newer tools occur around them for Python 3.4+ which won’t fit into their development chain. I’ve made notes on this before. For businesses using 2.7 you should at least have a plan for strong unit-test coverage and new code should be written as 3.4-compatible, to ease your journey into 3.x+.
Advice to developers of new packages in 2016: If you’re not worried about losing some of your potential users, you might focus just on Python 3.4+, you’ll lose around 60% of your potential userbase and this will move in your favour fairly quickly over the next 2 years. You might want to invest time in cross-compatibility using tools like __future__ and six if supporting Python 2.7 isn’t too complicated – the burden is heavier if you’re doing text processing and web-based data processing (as the bytes/str/unicode distinctions induce more pain). You probably shouldn’t focus solely on Python 2.7 as the trend is against you.
If you run a community group then maybe you’d like to make a survey like this?
I used SurveyMonkey, it is free if you have <100 respondents, I had buy a monthly plan to access these results. Here are some notes:
Community surveyed: London Python-using Data Scientists who are members of PyDataLondon, these are mainly industrial users (40% PdD, 40% MSc, the majority self-identify as being Practicing Data Scientists), some are academics. In the UK we’ve had various Python communities grow over the years including PyConUK (2007+), London Financial Python Usergroup (2009-2014), London Python Usergroup (2010+). Our PyDataLondon is 3 years old, it is also the largest active Python usergroup in Europe. The above results probably reflect (within a margin of error) the general state of Python-using Data Scientists in the UK.
Bias: Accepting the demographics of the audience noted above (i.e. self-selected professional and active individuals focused around London), I did observe an interesting bias in the distribution of results over time. I issued the survey 4 times over 1 week. At first I received clear evidence (approx 40 responses) that Python 3.4+ was used significantly at work. I wrote a second email to our meetup group strongly requesting more submissions and quickly this climbed to 200+. In this second tranche the dominance of Python 3.4 dropped and 2.7 edged forwards. After a 3rd and 4th email it was clear that Python 2.7 is dominant. Possibly the early responders are more vocal in their Python 3.4+ support?
Improving the questions: If I were to run the survey again (and if you want to run one like it) – I’d suggest changing the “Which distribution question do you use at work?” to “Which distribution do you use the majority of the time?” (removing ‘work’). I’d probably also add a new question with a short “Which industry do you primarily work in?” list of radio-boxes (e.g. Finance, Biotech, Gaming, Retail, Hardware, …). I think the break-down of Python 2.7 users against Industry might be interesting.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyDataLondon 2016 Conference Write-up
We’ve just run our 3rd PyDataLondon Conference (2016) – 3 days, 4 tracks, 330 people.This builds on PyDataLondon 2015. It was ace! If you’d like to be notified about PyDataLondon 2017 then join this announce list (it’ll be super low volume like it has been for the last 2 years).
Big thanks to the organizers, sponsors and speakers, such a great conference it was. Being super tired going home on the train, but it was totally worth it. – Brigitta

We held it at Bloomberg UK again – many thanks to our hosts! I’d also like to thank my colleagues, review committee and all our volunteers for their hard work, the weekend went incredibly smoothly and that’s because our team is so on-top-of-everything – thanks!
Our keynote speakers were:
- Professor Andreas Freise (@gwoptics) talking on LIGO and the discovery of gravity waves (video)
- Tetiana Ivanova on her journey into data science (video forthcoming)
- Travis Oliphant on the breadth of the Python data science toolset (video)
Our videos are being uploaded to YouTube. Slides will be linked against each author’s entry. There are an awful lot of happy comments on Twitter too. Our speakers covered Python, Julia, R, MCMC, clustering, geodata, financial modeling, visualisation, deployment, pipelines and a whole lot more. I spoke on Statistically Solving Sneezes and Sniffles (a citizen science project using ML to try to diagnose the causes of Rhinitis). Our Beginner Bootcamp (led by Conrad) had over 50 attendees!

…Let me second that. My first PyData also. It was incredible. Well organised – kudos to everyone who helped make it happen; you guys are pros. I found Friday useful as well, are the meetups like that? I’d love to be more involved in this community. – lewis
We had two signing sessions for five authors with a ton of free books to give away:
- Kyran Dale – Data Visualisation with Python and Javascript (these were the first copies in the UK!)
- Amit Nandi – Spark for Python Developers
- Malcolm Sherrington – Mastering Julia
- Rui Miguel Forte – Mastering Predictive Analytics with R
- Ian Ozsvald (me!) – High Performance Python (now in Italian, Polish and Japanese)

Some achievements
- We used slack for all members at the conference – attendees started side-channels to share tutorial files, discuss the meets and recommend lunch venues (!)
- We added an Unconference track (7 blank slots that anyone could sign-up for on the day), this brought us a nice random mix of new topics and round-table discussions
- A new bioinformatics slack channel is likely to be formed due to collaborations at the conference
- We signed up a ton of new volunteers to help us next year (thanks!)
- An impromptu jobs board appeared on a notice board and was rapidly filled (if useful – also see my jobs list)
Thank you to all the organisers and speakers! It’s been my first PyData and it’s been great! – raffo
We had 15-20% female attendance this year, a slight drop on last year’s numbers (we’ll keep working to do better).
On a personal note it was great to see colleagues who I’ve coached in the past – especially as some were speaking or were a part of our organising committee.
With thanks to our sponsors and via ticket sales we raised more money this year for the NumFOCUS non-profit that backs the scientific Python stack (they give grants and stipends for contributors). We’d love to have more sponsors next year (this is especially useful if you’re hiring!). Thanks to:
Let me know if you do a write-up so I can link it here please:
- Marco Bonzanini
- Matthew Mayo
- Marc Garcia
- Dr. Olivia Guest
- Lyst
- <your write-up>
If you’d like to hear about next year’s event then join this announce list (it’ll be super low volume). You probably also want to join our PyDataLondon meetup.
There are other upcoming PyData conferences including Berlin, Paris and Cologne. Take a look and get involved!
As an aside – if your data science team needs coaching, do drop me a line (and take a look at my coaching testimonials on LinkedIn). If you want a job in data science, take a look at my London Python data science jobs list.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Read my book

Oreilly High Performance Python by Micha Gorelick & Ian Ozsvald AI Consulting


Mor Consulting Ltd. is an A.I. focused consultancy offering strategic research and development owned by Ian Ozsvald, based in London (UK).
Co-organiser


PyData London provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.