Last weekend I had the pleasure of introducing Machine Learning for Engineers (a practical walk-through, no maths) [YouTube video] at PyConUK 2016. Each year the conference grows and maintains a lovely vibe, this year it was up to 600 people! My talk covered a practical guide to a 2 class classification challenge (Kaggle’s Titanic) with scikit-learn, backed by a longer Jupyter Notebook (github) and further backed by Ezzeri’s 2 hour tutorial from PyConUK 2014.
Topics covered include:
- Going from raw data to a DataFrame (notable tip – read Katharine’s book on Data Wrangling)
- Starting with a DummyClassifier to get a baseline result (everything you do from here should give a better classification score than this!)
- Switching to a RandomForestClassifier, adding Features
- Switching from a train/test set to a cross validation methodology
- Dealing with NaN values using a sentinel value (robust for RandomForests, doesn’t require scaling, doesn’t require you to impute your own creative values)
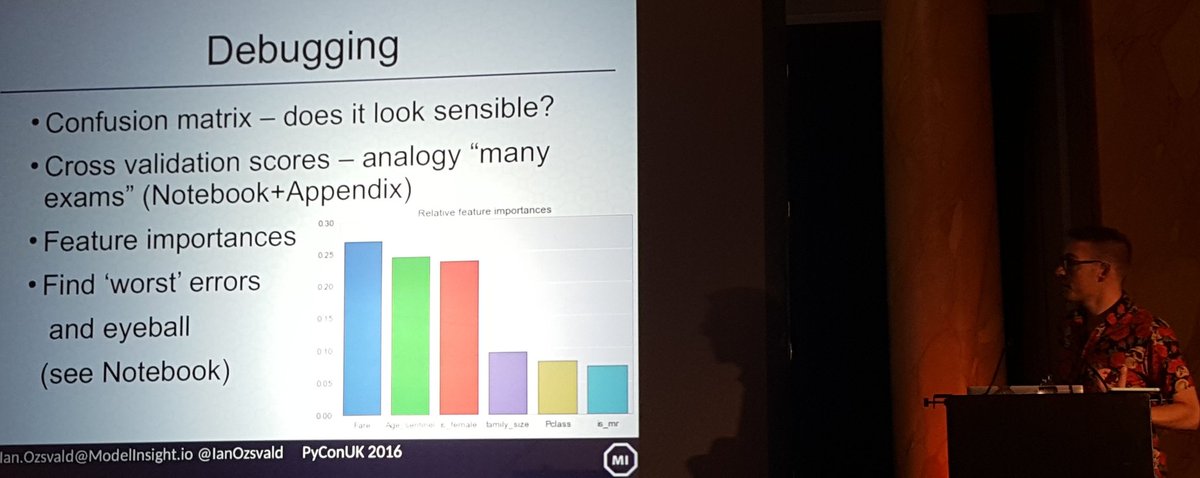
- Diagnosing quality and mistakes using a Confusion Matrix and looking at very-wrong classifications to give you insight back to the raw feature data
- Notes on deployment
I had to cover the above in 20 minutes, obviously that was a bit of a push! I plan to cover this talk again at regional meetups, probably with 30-40 minutes. As it stands the talk (github) should lead you into the Notebook and that’ll lead you to Ezzeri’s 2 hour tutorial. This should be enough to help you start on your own 2 class classification challenge, if your data looks ‘somewhat like’ the Titanic data.
I’m generally interested in the idea of helping more engineers get into data science and machine learning. If you’re curious – I have a longer set of notes called Data Science Delivered and some vague plans to maybe write a book (maybe) – for the book join the mailing list here if you’d like to hear more (no hard sell, almost no emails at the moment, I’m still figuring out if I should do this).
You might also want to follow-up on Katharine Jarmul’s data wrangling talk and tutorial, Nick Radcliffe’s Test Driven Data Analysis (with new automated TDD-for-data tool to come in a few months), Tim Vivian-Griffiths’ SVM Diagnostics, Dr. Gusztav Belteki’s Ventilator medical talk, Geoff French’s Deep Learning tutorial and Marco Bonzanini and Miguel ‘s Intro to ML tutorial. The videos are probably in this list.
If you like the above then do think on coming to our monthly PyDataLondon data science meetups near London Bridge.
PyConUK itself has grown amazingly – the core team put in a huge amount of effort. It was very cool to see the growth of the kids sessions, the trans track, all the tutorials and the general growth in the diversity of our community’s membership. I was quite sad to leave at lunch on the Sunday – next year I plan to stay longer, this community deserves more investment. If you’ve yet to attend a PyConUK then I strongly urge you to think on submitting a talk for next year and definitely suggest that you attend.
The organisers were kind enough to let Kat and myself do a book signing, I suggest other authors think on joining us next year. Attendees love meeting authors and it is yet another activity that helps bind the community together.

Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
9 Comments