Entrepreneurial Geekiness
Entrepreneurial Geekiness
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products. More about Ian here.
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products.


Coaching

Training

Jobs

Products

Consulting
On receiving the Community Leadership Award at the NumFOCUS Summit 2018
At the end of September I was honoured to receive the Community Leadership Award from NumFOCUS for my work building out the PyData community here in London and at associated events. This was awarded at the NumFOCUS 2018 Summit, I couldn’t attend the New York event and James Powell gave my speech on my behalf (thanks James!).
Congratulations to @kellecruz and @Microsoft 's Shahrokh Mortazavi and @ianozsvald for receiving @NumFOCUS awards last night at the annual event. Thanks to all past board members as well. Many thanks to staff! Become a sustaining member of this vital org: https://t.co/8mOEahZbTS
— Travis Oliphant (@teoliphant) September 24, 2018
I’m humbled to be singled out for the award – things only worked out so well because of the work of all of my colleagues (and alumni) at PyDataLondon and all the other wonderful folk at events like PyDataBerlin, PyDataAmsterdam, EuroPython (which has had a set of PyData sub-tracks) and PyConUK (with similar sub-tracks).
NumFOCUS posted a blog entry on the awards, in addition Kelle Cruz received the Project Sustainability Award and Shahrokh Mortazavi received the Corporate Stewardship Award.
Cecilia Liao and Emlyn Clay and myself started the first PyDataLondon conference in 2014 with lots of help, guidance and nudging from NumFOCUS (notably Leah – thanks!), James and via Continuum (now Anaconda Inc) Travis and Peter. Many thanks to you all for your help – we’re now at 8,000+ members and our monthly events have 200+ attendees thanks to AHL’s hosting.
PyData London is a fantastic achievement, and really helped me get started in a data science career. Many congratulations! https://t.co/ejhdooG8Hd
— PyData Cardiff (@pydatacardiff) September 24, 2018
If you don’t know NumFOCUS – they’re the group who do a lot of the background support for a number of our PyData ecosystem packages (including numpy, Jupyter and Pandas and beyond to R and Julia), back the PyData conference series and help lots of associated events and group. They’re a non profit and an awful lot of work goes on that you never see – if you’d like to provide financial support, you can setup a monthly sponsorship here. If you currently don’t provide any contributions back into our open source ecosystem – setting up a regular monthly payment is the easiest possible thing you could do to help NumFOCUS raise more money which helps more development occur in our ecosystem.
https://twitter.com/holdenweb/status/1044221855341645825
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyConUK 2018
Last weekend we had another fine PyConUK (2018) conference. Each year the conference grows, the Django Girls group had 70 or so women learning Django (and, often, Python for the first time). The kids hack day was a great success. The Pythonic-hardware demo session was fun.
Each year PyConUK encourages first-time speakers so we had the diverse-as-usual set of speakers and topics. If you’ve never attended – I’d encourage you to think on at least attending next year, and if you’re game do think about submitting a talk (even a 5 minute lightning talk as an easy first contribution).
This year I chaired two sets of sessions on the PyData track and spoke on the Diagramatic Diagnosis of Data. Slides are linked here (note that the PDF lacks some images and formatting), these are the PDF export from a live Jupyter Notebook presentation (here’s the repo).

I spoke on:
- Styling Pandas
- Initial exploratory data analysis using Google’s Facets and pandas_profiling
- Data story-telling using matplotlib and Seaborn
- Data stories by Bertil
- Data relationship discovery using my discover_feature_relationships to help prioritise which columns to investigate
Here’s the talk:
Pete Inglesby also ran a rather fun competition for us to write a Python based limited-opcode Connect 4 solver. You wrote some code, uploaded it and watched it battle the other entrants. For a little while I held 2nd place but I dropped by the finals to 7th. Here’s Pete’s botany code, Rob’s winning set of solutions and Sev’s bots.. Here’s the diagnostic session after the competition (I’d gone home a day before ). A few lessons learned:
- Analyse the bot failures against any default bots
- Play the bot by hand to see how kind of mistakes it makes
- Submitting many entries yields more information about placing than running local simulations (just as with Kaggle)
- Don’t trust the bot titles (“minimax” and others didn’t actually use that strategy)
- Don’t go complex early – check the simple ways you can lose and avoid these mistakes (I tried doing full-board scoring – that eats all of your scant opcodes in no time at all)
- Check for traps which will play out against you and block where possible
- A pre-calculated 8-ply deep solution, uploaded as a compressed data structure in the source file, is pretty sweet (this came 4th with no other strategies)
If you’re roughly in the area of Cardiff you might want to look at the PyDataCardiff and PyDataBristol meetups. They’d be great places for you to meet local community members and, perhaps, to practice giving a talk that you might later submit to PyConUK next year. If you’re in London then you’re very welcome to attend our PyDataLondon or maybe you’ll want to look at the London Python meetup.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
On the growth of our PyDataLondon community
I haven’t spoken on our PyDataLondon meetup community in a while so I figure a few numbers are due. We’re now at an incredible 7,800 members and just this month we had 200 members in the room at AHL’s new venue. We’re a volunteer run community – you’ll see the list of our brilliant volunteers here along with their Twitter accounts.
I polled the attendees this month and 1/3 of the hands went up (see below) to the question “Who is a first-timer to this meetup?”. This shows the continued growth in our community and in the wider data science ecosystem in London. Welcome along!

One of our talks was on Pandas v1, that included an update by Marc on how Python 2.x is being deprecated in Pandas next year and the new Cyberpandas and Fletcher (dtype extensions including faster strings) libraries. Marc also noted that Pandas is estimated to have 5-10 million users! One of the benefits of internal Pandas updates will be the “UInt8” and related dtypes – we’ll have integers with NaNs for the first time ever (previously int arrays with NaNs were promoted to floats which have NaN support in numpy).
Given the continued growth of our ecosystem – this means we have more Python newbies and more Data Science newbies (including converts moving away from Excel and SPSS). We’re always looking for new speakers. New speakers don’t have to be experienced data scientists – a 5 minute lightning talk on how you are transitioning in to this ecosystem from elsewhere can be hugely valuable to other new members. A talk (5 mins or 30 minutes) on a technique you’re experienced in – even if there’s no equivalent Python library – is also incredibly educational. Please come and share your knowledge.
Talking will raise your profile and it’ll raise your employer’s profile (if that’s what you’re after) and that obviously helps with hiring. We continue after the meetup in the local pub (typically The Banker) so anyone who’s been speaking and who ends with “and we’re hiring!” tends to have interesting conversations in the pub afterwards. With 200 attendees it isn’t hard to find folk who’d be interested in your role. Remember – this is most effective for speakers as you have the entire audience’s attention. You’ll find instructions here on how to submit a talk.
AHL continue to support our open source PyData world (along with other open events like the London Machine Learning meetup), they now rent a professional auditorium next to their building each month for us with full hosting, mics on every chair and video recording (see them at PyDataTV) for speakers who consent. This isn’t cheap of course and it provides evidence of the growth of Python’s Data Science stack in the London financial community. AHL’s activity at the meetup is to say a few words before the break about who they’re hiring for, before everyone heads out for more beer. Thanks AHL for your continued support! You might also want to check their github repo.
There’s a whole pile of PyData conferences coming up, you might find some are closer to you or your offices than you imagine. Go check the list. The PyData meetup ecosystem has grown world-wide to 111 events now too!
PyData of course is supported by NumFOCUS, the non-profit in the US. NumFOCUS backs a lot of our open source tools. They’re having a summit late this September in the US – everyone is welcome, if you’re interested in the deeper direction of Python and the Data Science community then you might want to attend (or send a representative from your group?).
Of course you might also want to be hired by a company that works in our PyData ecosystem. I post out jobs (UK-centric but they stretch to western Europe and sometimes to the US) every 2 weeks to 650+ data scientists and engineers, typically 7 roles (mostly permie, some contract, all Python focused). You might want to join that list (note your email is always kept private and is never shared). Attending PyData members (i.e. anyone who helps build our ecosystem) gets a first post gratis.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Keynote at EuroPython 2018 on “Citizen Science”
I’ve just had the privilege of giving my first keynote at EuroPython (and my second keynote this year), I’ve just spoken on “Citizen Science”. I gave a talk aimed at engineers showing examples of projects around healthcare and humanitarian topics using Python that make the world a better place. The main point was “gather your data, draw graphs, start to ask questions” – this is something that anyone can do.
Last day. Morning keynote by @IanOzsvald (sp.) “Citizen Science”.
#EuroPython Really cool talk! – @bz_sara

In the talk I covered 4 short stories and then gave a live demo of a Jupyter Lab to graph some audience-collected data:
- Gorjan‘s talk on Macedonian awful-air-quality from PyDataAmsterdam 2018
- My talks on solving Sneeze Diagnosis given at PyDataLondon 2017, ODSC 2017 and elsewhere
- Anna‘s talk on improving baby-delivery healthcare from PyDataWarsaw 2017
- Dirk‘s talk on saving Orangutangs with Drones from PyDataAmsterdam 2017
- Jupyter Lab demo on “guessing my dog’s weight” to crowd-source guesses which we investigate using a Lab
The goal of the live demo was to a) collect data (before and after showing photos of my dog) and b) show some interesting results that come out of graphing the results using histograms so that c) everyone realises that drawing graphs of their own data is possible and perhaps is something they too can try. Whilst having folk estimate my dog’s weight won’t change the world, getting them involved in collecting and thinking about data will, I hope, get more folk engaged outside of the conference.
The slides are here.
One of the audience members took some notes:

Here’s some output. Approximately 440 people participated in the two single-answer surveys. The first (poor-information estimate) is “What’s the weight of my dog in kg when you know nothing about the dog?” and the second (good-information estimate) is “The same, but now you’ve seen 8+ pictures of my dog”.
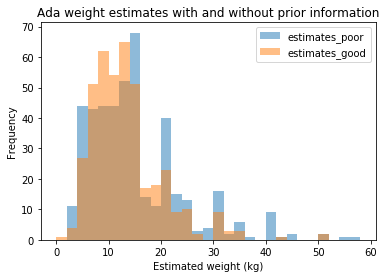
With poor information folk tended to go for the round numbers (see the spikes at 15, 20, 30, 35, 40). After the photos were shown the variance reduced (the talk used more graphs to show this), which is what I wanted to see. Ada’s actual weight is 17kg so the “wisdom of the crowds” estimate was off, but not terribly so and since this wasn’t a dog-fanciers crowd, that’s hardly surprising!
Before showing the photos the median estimate was 12.85kg (mean 14.78kg) from 448 estimates. The 5% quantile was 4kg, 95% quantile 34kg, so 90% of the estimates had a range of 30kg.
After showing the photos the median estimate was 12kg (mean 12.84kg) from 412 estimates. The 5% quantile was 5kg, 95% quantile 25kg, so 90% of the estimates had a range of 20kg.
There were only a couple of guesses above 80kg before showing the photos, none after showing the photos. A large heavy dog can weight over 100kg so a guess that high, before knowing anything about my dog, was feasible.
Around 3% of my audience decided to test my CSV parsing code during my live demo (oh, the wags) with somewhat “tricky” values including “NaN”, “None”, “Null”, “Inf”, “∞”, “-15”, “⁴4”, “1.00E+106”, “99999999999”, “Nana”, “1337” (i.e. leet!), “1-30”, “+[[]]” (???). The “show the raw values in a histogram” cell blew up with this input but the subsequent cells (using a mask to select only a valid positive range) all worked fine. Ah, live demos.
The slides conclude with two sets of links, one of which points the reader at open data sources which could be used in your own explorations. Source code is linked on my github.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
“Creating correct and capable classifiers” at PyDataAmsterdam 2018
This weekend I got to attend PyDataAmsterdam 2018 – this is my first trip to the Netherlands (Yay! It is lovely here). The conference grew on last year to 345 attendees with over 20% female speakers.
In addition to attending some lovely talks I also got to run another “Making your first open source contribution” session, with James Powell and a couple of people in 30 minutes we fixed some typos in Nick Radcliffe’s tdda project to improve his overview documentation. I’m happy to have introduced a couple of new people to the idea that a “contribution” can start with a 1 word typo-fix or adding notes to an existing bug report, without diving into the possibly harder world of making a code contribution.
We also had Segii along as our NumFOCUS representative (and Marci Garcia of the Pandas Sprints has done this before too). If you want to contribute to the community you might consider talking to NumFOCUS about how to be an ambassador at a future conference.
I gave an updated talk on my earlier presentation for PyDataLondon 2018, this time I spoke more on :
- YellowBrick‘s ROC curves
- SHAPley machine learning explanations
- Along with my earlier ideas on diagnosis using Pandas and T-SNE
I had a lovely room, wide enough that I only got a third of my audience in the shot below:

I’ve updated some of the material from my London talk, particularly I’ve added a few slides on SHAPley debugging approaches to contrast against ELI5 that I used before. I’ll keep pushing this notion that we need to be debugging our ML models so we can explain why they work to colleagues (if we can’t – doesn’t that mean we just don’t understand the black box?).
Checking afterwards it is lovely to get supportive feedback, thank you Ondrej and Tobias:
I went to this talk straight from the airport and I’m glad I made it. Ian shows a lot of passion for visual understanding of ML that leads to better understanding of complex models.
— Ondrej Kokes (@pndrej) May 26, 2018
Really neat visualization by @ianozsvald at @pydataamsterdam to inspect your predictions pic.twitter.com/g3INTDRXAE
— Tobias Sterbak (@tobias_sterbak) May 26, 2018
Here are the slides (the code has been added to my data_science_delivered github repo):
I’m really happy with the growth of our international community (we’re up to 100 PyData meetups now!). As usual we had 5 minute lightning talks at the close of the conference. I introduced the nbdime Notebook diff tool.
I’m also very pleased to say that I’ve had a lot of people come up to say Thanks after the talk. This is no doubt because I now highlight the amount of work done by volunteer conference organisers and volunteer speakers (almost everyone involved in running a PyData conference is an unpaid volunteer – organisers and speakers alike). We need to continue making it clear that contributing back to the open source ecosystem is essential, rather than just consuming from it. James and I gave a lightning talk on this right at the end.
Update – I’m very happy to see this tweet about how James’ and my little talk inspired Christian to land a PR. I’m also very happy to see this exchange with Ivo about potentially mentoring newer community members. I wonder where this all leads?
Great motivational speech by @dontusethiscode and @ianozsvald at #PyDataAmsterdam on contributing to open source projects. It finally gave me enough confidence to open my first pull-request to scikit-learn! https://t.co/Yyblr6Pdzb
— Christian Hirsch (@Christi16455258) May 31, 2018
If there are more like minded people, I'm definitely up for it
— Ivo Flipse (@ivoflipse5) May 29, 2018
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Read my book

Oreilly High Performance Python by Micha Gorelick & Ian Ozsvald AI Consulting


Mor Consulting Ltd. is an A.I. focused consultancy offering strategic research and development owned by Ian Ozsvald, based in London (UK).
Co-organiser


PyData London provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.