Entrepreneurial Geekiness
Entrepreneurial Geekiness
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products. More about Ian here.
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products.


Coaching

Training

Jobs

Products

Consulting
Data Science Training Survey
I’ve put together a short survey to figure out what’s needed for Python-based Data Science training in the UK. If you want to be trained in strong data science, analysis and engineering skills please complete the survey, it doesn’t need any sign-up and will take just a couple of minutes. I’ll share the results at the next PyDataLondon meetup.
If you want training you probably want to be on our training announce list, this is a low volume list (run by MailChimp) where we announce upcoming dates and suggest topics that you might want training around. You can unsubscribe at any time.
I’ve written about the current two courses that run in October through ModelInsight, one focuses on improving skills around data science using Python (including numpy, scipy and TDD), the second on high performance Python (I’ve now finished writing O’Reilly’s High Performance Python book). Both courses focus on practical skills, you’ll walk away with working systems and a stronger understanding of key Python skills. Your developer skills will be stronger as will your debugging skills, in the longer run you’ll develop stronger software with fewer defects.
If you want to talk about this, come have a chat at the next PyData London meetup or in the pub after.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyDataLondon 3rd event
This week we had our 3rd PyDataLondon meetup (@PyDataLondon), this builds on our 2nd event. We’re really happy to see the group grow to over 400 members, co-org Emlyn made a plot (see below) of our linear growth.

Our main speakers:
- Andrew Clegg (chief Data Scientist at Pearson Publishing in London) spoke on his Snake Charmer vagrant distribution of common Python science packages. They use it to quickly run new experiments using disposable virtual machines. Andrew’s slides are online along with his IPython Notebook
- Maria Rosario Mestre gave an introduction to Apache Spark based on recent usage at Skimlinks, the story was useful as it covered both pros and cons. We learned that Python is (currently) a second-class citizen, the API in general is rapidly evolving and debugging info is hard to come by – it feels not really ready for production usage (unless you want to put in additional hours). Slides here
- Emlyn Clay gave a lightning talk debunking the ‘brain machine interface’. Slides here
- I gave a lightning talk on my IPython Memory Usage Analyzer, slides here
Andrew’s talk gave a live demo of reading live wikipedia edit data and visualising, having rolled out a new environment using vagrant. This environment can be deleted and rebuilt easily allowing many local environments using entirely separate virtual box distributions:

Emlyn extracted the dates when each member joined the PyDataLondon meetup group, using this he plotted a cumulative growth chart. It looks rather like we have some growth ahead of us 🙂 The initial growth is after we announced the group at the start of May, a few months after our first conference. You can see some steps in the graph, that occurs during the run-up to each new event:
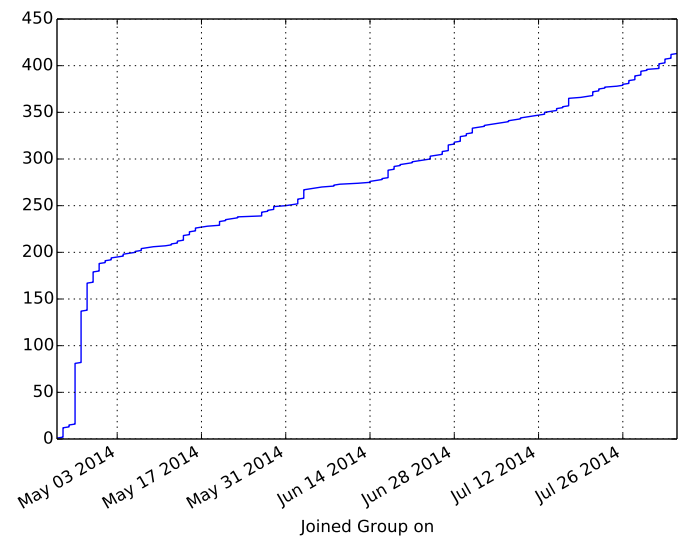
Emlyn announced the growth during our new ‘news segment’, he showed textract as his module of the month. Please humour him and feed us some new news for next month’s event 🙂 I also got to announce that my High Performance Python book is days away from going to the publisher after 11 months work – yay! We also discussed Kim’s S2D2 (in the news) and the new Project Jupyter.
We ran the “want & need” card experiment to build on last month’s experiment, this enabled some of us to meet just-the-right-people in the pub after to swap helpful notes:

Finally I also announced the upcoming training courses that my ModelInsight will be running October, there’s a blog post here detailing the Intro to Data Science and High Performance Python courses (or sign-up to our low-volume announce list).
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
A tiny foray into Apache Spark & Python
I’ve spent an afternoon playing with Apache Spark (1.0.1) to start to form an opinion on where it might be useful. Here’s a couple of notes. We’re discussing this at PyDataLondon tonight.
UPDATE I cover PySpark 1.2, ElasticSearch and PyPy in 2015.
You can run Spark out of the box on Linux (I’m using 13.10) without having Hadoop or HDFS installed, this makes quick experimentation easy. Having downloaded spark-1.0.1-bin-hadoop2.tgz I followed the README’s advice of running
./bin/pyspark
>>> sc.parallelize(range(1000)).count()
and indeed the PySpark command line interface popped up and the parallel job ran, on my local machine. I changed 1000 to 10,000,000 and it looked as though it was using multiple CPUs (though I won’t bet money on it).
The online doc is out of date for running the example programs (the Scala/Java demos are well documented), for the example Pi estimator I used:
.bin/spark-submit examples/src/main/python/pi.py
and it produced a similar result to the equivalent Scala program.
I did try to run PySpark with Python 3.4 but it is written for Python 2.7, the first stumbling block was the SocketServer module (now called socket_server in Python 3+) and I gave up there. I also tried using PyPy, it seems that PySpark starts with PyPy:
$ PYSPARK_PYTHON=~/Downloads/pypy-c-jit-69206-84efb3ba05f1-linux64/bin/pypy bin/pyspark
...
Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 1.0.1 /_/ Using Python version 2.7.3 (84efb3ba05f1, Feb 18 2014) SparkContext available as sc. And now for something completely different: ``samuele says that we lost arazor. so we can't shave yaks''
If I try to run the Pi estimator with PyPy then it has a deeper error with “PicklingError: Can’t pickle builtin <type ‘method’>” so I gave up there.
From what I can see Python 2.7 and numpy (>=1.4) are supported, their dev guide does note that Py 2.6+2.7 are the only two supported. I’ve not tried using HDFS (it looks like it’ll take <1/2 day to setup on a single machine but I didn’t need it for this first foray). It looks like IPython was (and maybe should) be supported in 0.8.1 but I couldn’t get it to run with pyspark 1.0.1 (possible solution that I’ve not tested yet).
MLlib seems to support scipy (e.g. Sparse arrays) and Numpy which goes down to netlib and jblas (java versions of BLAS/lapack/etc wrappers).
Update – At the PyDataLondon event it was noted that Python is currently a second-class citizen (with Scala as first-class) and that Python incurs a 2* memory overhead (I believe that numpy data gets copied into Spark’s system) – if anyone has better knowledge and could leave a comment, that’d be ace.
I also see that the k-means approach (k-means-||) is parallelised but for the other ML algorithms it isn’t clear if they are parallelised. If they’re not, what’s the point of building a distributed set of classifiers? I fear I’m missing something here – if you have an opinion, I’d love to see it.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Python Training courses: Data Science and High Performance Python coming in October
I’m pleased to say that via our ModelInsight we’ll be running two Python-focused training courses in October. The goal is to give you new strong research & development skills, they’re aimed at folks in companies but would suit folks in academia too. UPDATE training courses ready to buy (1 Day Data Science, 2 Day High Performance).
UPDATE we have a <5min anonymous survey which helps us learn your needs for Data Science training in London, please click through and answer the few questions so we know what training you need.
“Highly recommended – I attended in Aalborg in May “@ianozsvald:… upcoming Python DataSci/HighPerf training courses”” @ThomasArildsen
These and future courses will be announced on our London Python Data Science Training mailing list, sign-up for occasional announces about our upcoming courses (no spam, just occasional updates, you can unsubscribe at any time).
Intro to Data science with Python (1 day) on Friday 24th October
Students: Basic to Intermediate Pythonistas (you can already write scripts and you have some basic matrix experience)
Goal: Solve a complete data science problem (building a working and deployable recommendation engine) by working through the entire process – using numpy and pandas, applying test driven development, visualising the problem, deploying a tiny web application that serves the results (great for when you’re back with your team!)
- Learn basic numpy, pandas and data cleaning
- Be confident with Test Driven Development and debugging strategies
- Create a recommender system and understand its strengths and limitations
- Use a Flask API to serve results
- Learn Anaconda and conda environments
- Take home a working recommender system that you can confidently customise to your data
- £300 including lunch, central London (24th October)
- Additional announces will come via our London Python Data Science Training mailing list
- Buy your ticket here
High Performance Python (2 day) on Thursday+Friday 30th+31st October
Students: Intermediate Pythonistas (you need higher performance for your Python code)
Goal: learn high performance techniques for performant computing, a mix of background theory and lots of hands-on pragmatic exercises
- Profiling (CPU, RAM) to understand bottlenecks
- Compilers and JITs (Cython, Numba, Pythran, PyPy) to pragmatically run code faster
- Learn r&d and engineering approaches to efficient development
- Multicore and clusters (multiprocessing, IPython parallel) for scaling
- Debugging strategies, numpy techniques, lowering memory usage, storage engines
- Learn Anaconda and conda environments
- Take home years of hard-won experience so you can develop performant Python code
- Cost: £600 including lunch, central London (30th & 31st October)
- Additional announces will come via our London Python Data Science Training mailing list
- Buy your ticket here
The High Performance course is built off of many years teaching and talking at conferences (including PyDataLondon 2013, PyCon 2013, EuroSciPy 2012) and in companies along with my High Performance Python book (O’Reilly). The data science course is built off of techniques we’ve used over the last few years to help clients solve data science problems. Both courses are very pragmatic, hands-on and will leave you with new skills that have been battle-tested by us (we use these approaches to quickly deliver correct and valuable data science solutions for our clients via ModelInsight). At PyCon 2012 my students rated me 4.64/5.0 for overall happiness with my High Performance teaching.
“@ianozsvald [..] Best tutorial of the 4 I attended was yours. Thanks for your time and preparation!” @cgoering
We’d also like to know which other courses you’d like to learn, we can partner with trainers as needed to deliver new courses in London. We’re focused around Python, data science, high performance and pragmatic engineering. Drop me an email (via ModelInsight) and let me know if we can help.
Do please join our London Python Data Science Training mailing list to be kept informed about upcoming training courses.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
IPython Memory Usage interactive tool
I’ve written a tool (ipython_memory_usage) to help my colleague and I understand how RAM is allocated for large matrix work, it’ll work for any large memory allocations (numpy or regular Python or whatever) and the allocs/deallocs are reported after every command. Here’s an example – we make a matrix of 10,000,000 elements costing 76MB and then delete it:
IPython 2.1.0 -- An enhanced Interactive Python.
In [1]: %run -i ipython_memory_usage.py
In [2]: a=np.ones(1e7)
'a=np.ones(1e7)' used 76.2305 MiB RAM in 0.32s,
peaked 0.00 MiB above current, total RAM usage 125.61 MiB
In [3]: del a
'del a' used -76.2031 MiB RAM in 0.10s,
peaked 0.00 MiB above current, total RAM usage 49.40 MiB
UPDATE As of October 2014 I’ll be teaching High Performance Python and Data Science in London, sign-up here to get on our course announce list (no spam, just occasional updates about upcoming courses). We’ll cover topics like this one from beginners to advanced, using Python, to do interestinng science and to give you the edge.
The more interesting behaviour is to check the intermediate RAM usage during an operation. In the following example we’ve got 3 arrays costing approx. 760MB each, they assign the result to a fourth array, overall the operation adds the cost of a temporary fifth array which would be invisible to the end user if they’re not aware of the use of temporaries in the background:
In [2]: a=np.ones(1e8); b=np.ones(1e8); c=np.ones(1e8)
'a=np.ones(1e8); b=np.ones(1e8); c=np.ones(1e8)'
used 2288.8750 MiB RAM in 1.02s,
peaked 0.00 MiB above current, total RAM usage 2338.06 MiB
In [3]: d=a*b+c
'd=a*b+c' used 762.9453 MiB RAM in 0.91s,
peaked 667.91 MiB above current, total RAM usage 3101.01 MiB
If you’re running out of RAM when you work with large datasets in IPython, this tool should give you a clue as to where your RAM is being used.
UPDATE – this works in IPython for PyPy too and so we can show off their homogeneous memory optimisation:
# CPython 2.7 In [3]: l=range(int(1e8)) 'l=range(int(1e8))' used 3107.5117 MiB RAM in 2.18s, peaked 0.00 MiB above current, total RAM usage 3157.91 MiB
And the same in PyPy:
# IPython with PyPy 2.7 In [7]: l=[x for x in range(int(1e8))] 'l=[x for x in range(int(1e8))]' used 763.2031 MiB RAM in 9.88s, peaked 0.00 MiB above current, total RAM usage 815.09 MiB
If we then add a non-homogenous type (e.g. adding None to the ints) then it gets converted back to a list of regular Python (heavy-weight) objects:
In [8]: l.append(None) 'l.append(None)' used 3850.1680 MiB RAM in 8.16s, peaked 0.00 MiB above current, total RAM usage 4667.53 MiB
The inspiration for this tool came from a chat with my colleague where we were discussing the memory usage techniques I discussed in my new High Performance Python book and I realised that what we needed was a lighter-weight tool that just ran in the background.
My colleague was fighting a scikit-learn feature matrix scaling problem where all the intermediate objects that lead to a binarised matrix took >6GB on his 6GB laptop. As a result I wrote this tool (no, it isn’t in the book, I only wrote this last Saturday!). During discussion (and later validated with the tool) we got his allocation to <4GB so it ran without a hitch on his laptop.
UPDATE UPDATE excitedly I’ll note (and this will be definitely exciting to about 5 other people too including at least @FrancescAlted) that I’ve added proto-perf-stat integration to track cache misses and stalled CPU cycles (whilst waiting for RAM to be transferred to the caches), to observe which operations cause poor cache performance. This lives in a second version of the script (same github repo, see the README for notes). I’ve also experimented with viewing how NumExpr makes far more efficient use of the cache compared to regular Python.
I’m probably going to demo this at a future PyDataLondon meetup.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Read my book

Oreilly High Performance Python by Micha Gorelick & Ian Ozsvald AI Consulting


Mor Consulting Ltd. is an A.I. focused consultancy offering strategic research and development owned by Ian Ozsvald, based in London (UK).
Co-organiser


PyData London provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.