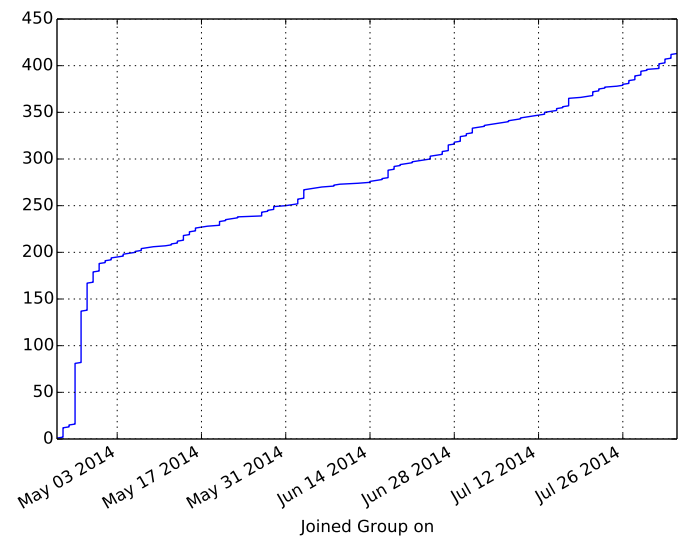
This week we had our 3rd PyDataLondon meetup (@PyDataLondon), this builds on our 2nd event. We’re really happy to see the group grow to over 400 members, co-org Emlyn made a plot (see below) of our linear growth.

Our main speakers:
- Andrew Clegg (chief Data Scientist at Pearson Publishing in London) spoke on his Snake Charmer vagrant distribution of common Python science packages. They use it to quickly run new experiments using disposable virtual machines. Andrew’s slides are online along with his IPython Notebook
- Maria Rosario Mestre gave an introduction to Apache Spark based on recent usage at Skimlinks, the story was useful as it covered both pros and cons. We learned that Python is (currently) a second-class citizen, the API in general is rapidly evolving and debugging info is hard to come by – it feels not really ready for production usage (unless you want to put in additional hours). Slides here
- Emlyn Clay gave a lightning talk debunking the ‘brain machine interface’. Slides here
- I gave a lightning talk on my IPython Memory Usage Analyzer, slides here
Andrew’s talk gave a live demo of reading live wikipedia edit data and visualising, having rolled out a new environment using vagrant. This environment can be deleted and rebuilt easily allowing many local environments using entirely separate virtual box distributions:

Emlyn extracted the dates when each member joined the PyDataLondon meetup group, using this he plotted a cumulative growth chart. It looks rather like we have some growth ahead of us 🙂 The initial growth is after we announced the group at the start of May, a few months after our first conference. You can see some steps in the graph, that occurs during the run-up to each new event:
Emlyn announced the growth during our new ‘news segment’, he showed textract as his module of the month. Please humour him and feed us some new news for next month’s event 🙂 I also got to announce that my High Performance Python book is days away from going to the publisher after 11 months work – yay! We also discussed Kim’s S2D2 (in the news) and the new Project Jupyter.
We ran the “want & need” card experiment to build on last month’s experiment, this enabled some of us to meet just-the-right-people in the pub after to swap helpful notes:

Finally I also announced the upcoming training courses that my ModelInsight will be running October, there’s a blog post here detailing the Intro to Data Science and High Performance Python courses (or sign-up to our low-volume announce list).
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
1 Comment