Entrepreneurial Geekiness
Entrepreneurial Geekiness
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products. More about Ian here.
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products.


Coaching

Training

Jobs

Products

Consulting
First PyDataLondon meetup done, preparing the second
Last night we ran our first PyDataLondon meetup (@PyDataLondon). We had 80 data-focused Pythonistas in the room, co-organiser Emlyn lead the talks followed by a great set of Lightning Talks. Pivotal provided a cool venue (thanks Ian Huston!) with lovely pizza and beer in central Shoreditch – we’re much obliged to you. This was a grand first event and we look forward to running the next set this summer. Our ModelInsight got to sponsor the beers for everyone after, it was lovely to see everyone in the pub – helping to bind our young community is one of our goals for this summer.
Emlyn opened with a discussion on “MATLAB and Python for Life Sciences” covering syntax similarities, ways to port MATLAB libraries to Python and hardware interfacing:

After the break we had a wide range of lightning talks:
- Jacqui Taylor on Data Journalism and Visualisation for Journalists
- Chipp Jansen (pic) on using Kinect through Python for stone carving (we want a live demo in a few months please!)
- Ben (pic) on NLP and ML on Beer Reviews
- Giles (pic) on Monte Carlo based clustering to beat Gephi’s clustering tools
- Ian Huston (pic) introduced Pivotal’s open source stack including Redis (I didn’t know before that Redis was supported here!) and did a 10-book giveaway
- Pete Inglesby (pic) reminding everyone to attend PyConUK and to announce an OpenCorporates update
- Kim Nilsson on her Science to DataScience summer school (opening this summer for PhDs in London)
- The PyLadiesLondon Justine, Linda and Nicola introduced their group to encourage attendance
- [Chipp please send me your twitter account!]
Here’s Jacqui talking on Viz using Python and D3 and introducing her part in the new Data Journalism book:
During the night I asked some questions of the audience. We had a room of mostly active Python users (mainly beginner or intermediate), the majority worked with data science on a weekly basis, almost all using Python 2 (not 3). 6 used R, 2 used MATLAB and 1 used Julia (and I’m still hoping to learn about Julia). A part of the reason for the question is that I’m interested in learning who needs what in our new community, I’m planning on re-running my 2 day High Performance Python tutorial in London in a couple of months and we aim to run an introduction to data science using Python too (mail me if you want to know more).
We’re looking for talk proposals for next month and the month after along with lightning talk proposals – either mail me or post via the meetup group (but do it quick).
I totally failed to remind everyone about the upcoming PyDataBerlin conference in Berlin in July, it runs inside EuroPython at the same venue (so come and stay all week, a bunch of us are!). I also forgot to announce EuroSciPy which runs here in Cambridge in August, you should definitely come to that too, I believe I’m teaching more High Performance Python.
The next event will be held on July 1st at the same location, keep an eye on the meetup group for details. I’m hoping next time to maybe put forward a Lightning Talk around my High Performance Python book as hopefully it’ll be mostly finished by then.
Thanks to my co-organisers Emlyn and Cecilia (and Florian – get well soon)!
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
New High Performance Python chapters online & teaching a 2 day course on HPC
The last month has been crazy busy, not least because I got to run my first High Performance Python 2 day tutorial at a university. I was out in Aalborg University teaching a PhD group, we covered four blocks:
- Profiling (CPU and RAM)
- Compilers and JITs
- Multi-core and distributed
- Using less RAM, storage systems and lessons
UPDATE As of October 2014 I’ll be teaching High Performance Python and Data Science in London, sign-up here to join our announce list (no spam, just occasional updates about our courses).
Here’s a picture of my class, it all went rather swimmingly. I plan to run the same class in London in the coming months (details to follow):

On the same note we pushed some more chapters for our High Performance Python book on to O’Reilly’s build system a week back, we now have:
- Introduction
- Performant Python
- Tuples and Dictionaries
- Iterators and Generators
- Profiling
- Matrices with numpy
- Compiling and JITs
More chapters will go live in a couple of weeks, we’re in the final editing phase now.
Don’t forget that PyDataBerlin is coming up in a couple of months, it runs during EuroPython. If you’re out for EuroPython then it makes a lot of sense to go to PyDataBerlin too 🙂
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyDataLondon Meetup Number 1 (June – JS, NLP, Kinects)
Our first PyData London Meetup will occur on June 3rd at Pivotal in Shoreditch. At our first night we’ll have:
- Pete Passaro talking on javascript and natural language processing using Python
- Emlyn Clay on Matlab and Python for science
- Chipp Jansen on auto-sculpting with a Kinect
- Ian Huston on Pivotal’s open source tools (I had no idea they supported Redis and so many other tools!)
- <1 more, TBC – submit an idea if you’re interested>
After this we’ll head to a local pub. Details will be announced via @pydatalondon. I haven’t run an event since the Five Pound App nights down in Brighton, I’m rather looking forward to getting data-focused Pythonistas together for interesting talks and good beer 🙂
This new meetup will occur every month, it builds on the success of our PyData London conference back in February, we had over 200 people and a lot of rather superb presentations. My time to run the PyData London meetup is supported by my new ModelInsight Data Science consultancy.
You might also be interested in Yves’ new Python for Quant Finance meetup.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
2nd Early Release of High Performance Python (we added a chapter)
Here’s a quick book update – we just released a second Early Release of High Performance Python which adds a chapter on lists, tuples, dictionaries and sets. This is available to anyone who has bought it already (login into O’Reilly to get the update). Shortly we’ll follow with chapters on Matrices and the Multiprocessing module.
One bit of feedback we’ve had is that the images needed to be clearer for small-screen devices – we’ve increased the font sizes and removed the grey backgrounds, the updates will follow soon. If you’re curious about how much paper is involved in writing a book, here’s a clue:

We announce each updates along with requests for feedback via our mailing list.
I’m also planning on running some private training in London later in the year, please contact me if this is interesting? Both High Performance and Data Science are possible.
In related news – the PyDataLondon conference videos have just been released and you can see me talking on the High Performance Python landscape here.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
High Performance Book almost ready for Early Release preview
Our first few chapters of High Performance Python are nearly ready for the Early Release on O’Reilly’s platform, we’ll be releasing:
- Understanding Performance Python (an overview of the virtual machine and modern PC hardware)
- Profiling Python Code (for CPU and RAM profiling, lots of options)
- Pure Python (generators, the guts of dicts and the like)
We’ll announce the release via our mailing list, sign-up if you want to know as soon as it is available. Overall Micha and I have written half the book now (although this first Early Release will be just the first 3 chapters), we aim to finish the other half in the next few months.
The process of writing is very iterative…which means it is far too easy to write a bunch of stuff and then realise there’s a bunch of holes that need filling in (some of which turn into real rabbit-holes one call fall into for days!). Out the other side you get a nice narrative, lots of verified results and some nice explanatory plots. It just takes rather a long time to get there.
Here’s the first couple of pages of the start of the (just being written-up) multiprocessing chapter, I’m using a Monte Carlo Pi estimator to discuss performance characteristics of threads vs processes. Notice the black pen and scrawls to improves the diagrams – this happens a lot:

Right now I’ve been playing with Pi estimation using straight Python and numpy over many cores using both threads and processes (this chapter is just looking at multiprocessing, not JITs or compilers [that’s a later chapter]). Processes obviously provide a linear speed-up for this sort of problem, exploring the right number of processes and the right job sizes (especially for variable-time workloads) was fun.
Threads on numpy do something interesting – you can actually use multiple cores and so code can run faster (about 10% in this case compared to a single core), although they’re often not as efficient as using multiple processes. Here’s a plot of CPU use for 4 cores (and 4 HyperThreads) over time with threads. It turns out that the random number generation is GIL bound but the vectorised operations for Pi’s estimation aren’t: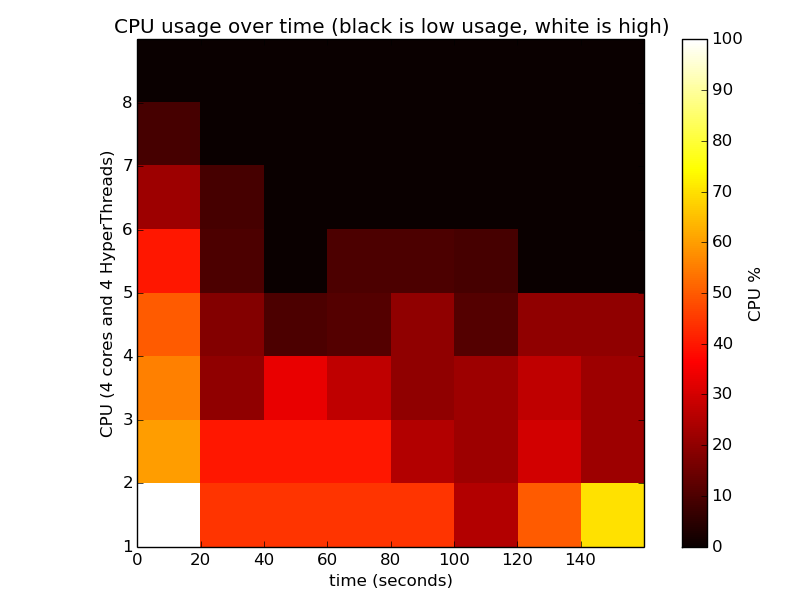
Join the mailing list for updates. Work on the book is supported via my London based Artificial Intelligence agency Mor Consulting.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Read my book

Oreilly High Performance Python by Micha Gorelick & Ian Ozsvald AI Consulting


Mor Consulting Ltd. is an A.I. focused consultancy offering strategic research and development owned by Ian Ozsvald, based in London (UK).
Co-organiser


PyData London provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.