Entrepreneurial Geekiness
Entrepreneurial Geekiness
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products. More about Ian here.
Ian is a London-based independent Chief Data Scientist who coaches teams, teaches and creates data products.


Coaching

Training

Jobs

Products

Consulting
12th PyDataLondon meetup at AHL
We’ve just had our 12th meetup – we’re fully a year old, we’ve nearly 1,500 members and now we’re planning our second conference (the Call for Proposals is open for just another 10 days!). Python Data Science has grown crazily-popular in the last couple of years!
Here’s a photo from last week’s meetup, that’s over 220 people at our new host hedge-fund AHL (they’re hiring):

Our two speakers were:
- Slavi Marinov talking on using gensim for topic classification for financial prediction
- Lasse Bohling talking on using statistics for football prediction at footballradar.com
Slides are linked in the meetup comments. We’ll take a break for a month to run the conference (June 19-21), then we’ll pick up again in July.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
“#talkpay” tweet salary visualisation
This weekend the #talkpay tag has shown people outing their salaries, to democratise some of this information. This provides some interesting data for visualisation. If you’re curious about a discussion around salary data then @patio11’s blog entry is a good starting point.
@echen grabbed some of the data, I took a copy of the online sheet and made the following code to visualise the salaries. This is a very simplistic analysis, it is mostly US data, there’s no filtering for location (you’d expect San Francisco to pay significantly more than many other US cities).
First, here’s a histogram of the majority of the salaries listed (ignoring the top-9 which go up to $1.1 million which distort the plot):

Next we can filter by some text terms, here’s a similar histogram for software developers. Note the interesting peaks at $80k and $120k, then smaller but obvious bumps at $150k, $200k and $250k:

There’s much less data for teachers but you can get an idea of the difference in likely salaries:

Finally we can plot a normed (summed to 1.0) cumulative histogram, you can think of the data as probabilities to get an idea of the proportion of people who earn less/more than a certain amount:

It is worth remembering that the data is thin, just 800 samples, it is also self-reported so most of the reports will be from people who are confident in being public. It is likely that the true distribution of salaries is lower, as people who aren’t confident are less likely to publish.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyDataLondon Conference 2015 Call for Proposals now OPEN (yay!) for June 19-21
PyDataLondon 2015 will take place June 19-21 at Bloomberg’s HQ in Central London, we’ll have 300 people, multiple tracks and a very solid set of speakers and teachers. You should come. You should probably speak and share your knowledge. In fact – you should submit a talk to our Call for Proposals, it opens this weekend and closes May 18th So You Don’t Have Long!
We have a set of Themes for the talks:
- Medical and Bioinformatics
- Tools (libraries, IDEs, hardware – whatever feels like a tool)
- FinTech and Economics
- Ecommerce and AdTech
- Other goodies (including Art, Open Data, Data Journalism, NGOs, Gaming, IoTs and Robotics – but open to whatever you think is going to be interesting)
The first three topics are definitely of interest to companies in London, Tooling is important to everyone and the “Other goodies” theme is the catch-all for stuff that’s of interest beyond the normal body of companies we know about. The CfP is only open for less than 3 weeks so don’t hang around! Get a title and short abstract down on paper first and then you can fill in the rest online easily enough.
This conference builds upon PyDataLondon 2014 Conference, we had 200 people last year at the top of Canary Wharf last year. This year we’ll be 50% bigger and in the centre of London. You want to come along!
Please forward this around to people who will find it interesting! We’re keen to have an even wider community than our usual 1,400 PyDataLondon meetup members, we’re friendly for non-Python talks (data science is our focus) and we’d love submissions from people around R, SAS, Julia, Hadoop and the like. Our CfP review committee is 50% female, 50% male, more industrial than academic and they’re all deeply active in the field. We want speakers covering beginner, intermediate and expert data science topics, don’t hold off if you’ve never spoken before, we’d love for you to get involved.
If you’re hiring then you’ll probably want to sponsor – we’ve already closed the first few sponsorship slots and the next set are under discussion so you should get in touch quickly. By sponsoring you’ll be visible to our 300 world-class actively-practising data scientists and you’ll get to meet the creative academic minds and active businesses in our London data science community. Seriously, you should sponsor and get involved, don’t hang around or you’ll be left with that little table at the end of the corridor and you don’t want that!
If you’re interested in the above then you might also be interested in PyConSweden (May 12-13) – I’m giving the Opening Keynote on Data Science Deployed (it’ll be written up here later) and there’s a set of very nice data science talks in the schedule. Very shortly after we’ll have PyDataBerlin on May 29-30 in the heart of Berlin, go grab your tickets before they sell out.
Even if you can’t make our conferences do please join our monthly PyDataLondon meetup and get involved in our very active community. You’ll find slides from past presenters in the Comments for each of the meetups.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
A review of ModelInsight’s growth this last year
Early last year Chris and I founded ModelInsight, a boutique Python-focused Data Science agency in London. We’ve grown well, I figure some reflection is in order. In addition the Data Science scene has grown very well in London, I’ll put some notes on that down below too.
Through consulting, training, workshops and coaching we’ve had the pleasure of working with the likes of King.com, Intel, YouGov and ElevateDirect. Each project aimed to help our client identify and use their data more effectively to generate more business. Projects have included machine learning, natural language processing, prediction, data extraction for both prototyping and deploying live services.
I’ve particularly enjoyed the training and coaching. We’ve run courses introducing data science with Python, covering stats and scikit-learn and high performance Python (based on my book), if you want to be notified of future courses then please join our training announce list.
With the coaching I’ve had the pleasure of working with two data scientists who needed to deploy reliably-working classifiers faster, to automate several human-driven processes for scale. I’ve really enjoyed the challenges they’re posing. If your team could do with some coaching (on-site or off-site) then get in touch, we have room for one more coaching engagement.
I’ve also launched my first data-cleaning service at Annotate.io, it aims to save you time during the early data-cleaning part of a new project. I’d value your feedback and you can join an announce list if you’d like to follow the new services we have planned that’ll make data-cleaning easier.
All the above occurs because the Data Science scene here in London has grown tremendously in the last couple of years. I co-organise the PyDataLondon meetup (over 1,400 members in a year!), here’s a chart showing our month-on-month growth. At Christmas it turned up a notch and it just keeps growing:
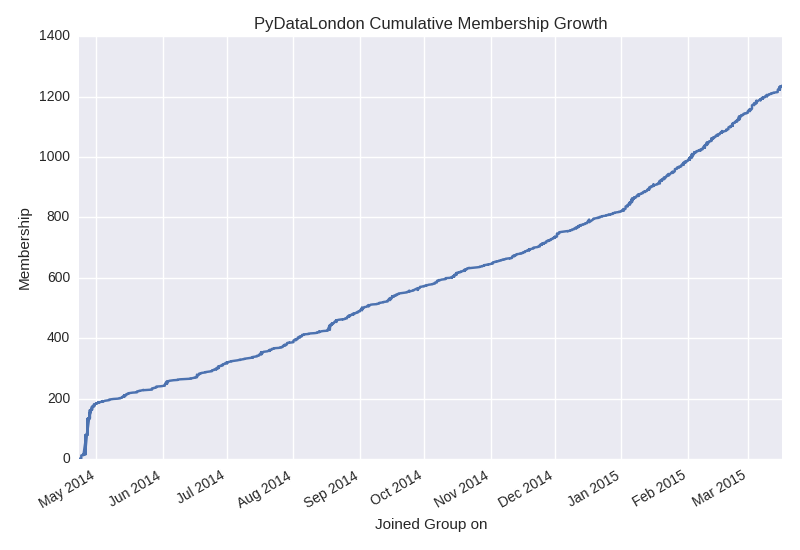
Each month we have 150-200 people in the room for strong Data Science talks, in a couple of months we’ll have our second conference with 300 people at Bloomberg (CfP announce list). We’re actively seeking speakers – join that list if you’d like to know when the CfP opens.
I’ve been privileged to speak as the opening keynoter on The Real Unsolved Problems in Data Science last year at PyConIreland, I’ve just spoken on data cleaning at PyDataParis and soon I’ll keynote on Data Science Deployed at PyConSE. I’m deeply grateful to the community for letting me share my experience. My goal is to help more companies utilise their data to improve their business, if you’ve got ideas on how we could help then I’d love to hear from you!
I’m also thinking of writing a book on Building Python Data Science Products, see the link for some notes, it’ll cover 15 years of hard-won advice in building and shipping successful data science products using Python.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
PyDataParis 2015 and “Cleaning Confused Collections of Characters”
I’m at PyDataParis, this is the first PyData in France and we have a 300-strong turn-out. In my talk I asked about the split of academic and industrial folk, we have 70% industrialists here (at least – in my talk of 70 folk). The bulk of the attendees are in the Intro track and maybe the split is different in there. All slides are up, videos are following, see them here.
Here’s a photo of Gael giving a really nice opening keynote on Scikit-Learn:

I spoke on data cleaning with text data, I packed quite a bit into my 40 minutes and got a nice set of questions. The slides are below, it covers:
- Data extraction from text files, PDF, HTML/XML and images
- Merging on columns of data
- Correctly processing datetimes from files and the dangers of relying on the pandas defaults
- Normalising text columns so we could join on otherwise messy data
- Automated data transformation using my annotate.io (Python demo)
- Ideas on automated feature extraction
- Ideas on automating visualisation for new, messy datasets to get a “bird’s eye view”
- Tips on getting started – make a Gold Standard!
One question concerned the parsing of datetime strings from unusual sources. I’d mentioned dateutil‘s parser in the talk and a second parser is delorean. In addition I’ve also seen arrow (an extension of the standard datetime) which has a set of parsers including one for ISO8601. The parsedatetime module has an NLP module to convert statements like “tomorrow” into a datetime.
I don’t know of other, better parsers – do you? In particular I want one that’ll take a list of datetimes and return one consistent converter that isn’t confused by individual instances (e.g. “1/1” is MM/DD or DD/MM ambiguous).
I’m also asking for feedback on the subject of automated feature extraction and automated column-join tools for messy data. If you’ve got ideas on these subjects I’d love to hear from you.
In addition I was reminded of DiffBot, it uses computer vision and NLP to extract meaning from web pages. I’ve never tried it, can any of you comment on its effectiveness? Olivier Grisel mentioned pyquery to me, it is an lxml parser which lets you make jquery-like queries on HTML.
update I should have mentioned chardet, it detects encodings (UTF8, CP1252 etc) from raw text, very useful if you’re trying to figure out the encoding for a collection of bytes off of a random data source! libextract (write-up) looks like a young but nice tool for extracting text blocks from HTML/XML sources, also goose. boltons is a nice collection of bolton-tools to the standard library (e.g. timeutils, strutils, tableutils). Possibly mETL is a useful tool to think about the extract, transform and load process.
update It might also be worth noting some useful data sources from which you can extract semi-structured data, e.g. ‘tech tags’ from stackexchange‘s forums (and I also see a new hackernews dump). Here’s a big list of “awesome public datasets“.
update Peadar Coyle (@springcoil) gave a nice talk at PyConItaly 2015 on “Data Products – how to get models into production” which is related.
Camilla Montonen has just spoken on Rush Hour Dynamics, visualising London Underground behaviour. She noted graph-tool, a nice graphing/viz library I’d not seen before. Fabian has just shown me his new project, it collects NLP IPython Notebooks and lists them, it tries to extract titles or summaries (which is a gnarly sub-problem!). The AXA Data Innovation Lab have a nice talk on explaining machine learned models.
Gilles Loupe’s slides for his ML/sklearn talk on trees and boosting are online, as are Alexandre Gramfort‘s on sklearn linear models.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
Read my book

Oreilly High Performance Python by Micha Gorelick & Ian Ozsvald AI Consulting


Mor Consulting Ltd. is an A.I. focused consultancy offering strategic research and development owned by Ian Ozsvald, based in London (UK).
Co-organiser


PyData London provides a forum for the international community of users and developers of data analysis tools to share ideas and learn from each other.