Below I’ve visualised tweets for #PyData conference and the cities of London and Brighton – this builds on my ‘concept cloud‘ from a few days ago at the #PyCon conference. Props to Maksim for his Social Media Analysis tutorial for inspiration.
Update – Maksim’s Analying Social Networks tutorial video is online.
For the earlier #PyCon 2013 analysis I visualised #hashtags and @usernames from #pycon tagged tweets during the conference. I’ve built upon this to add some natural language processing for ‘noun phrase extraction’ which I detail below – this helps me to pull out phrases that are descriptive but haven’t been tagged. It also helps us to see which people are connected with which subjects. For the PyCon analysis I collected 22k tweets, after removing retweets I was left with 7,853 for analysis.
#PyData (PyData Santa Clara 2013)
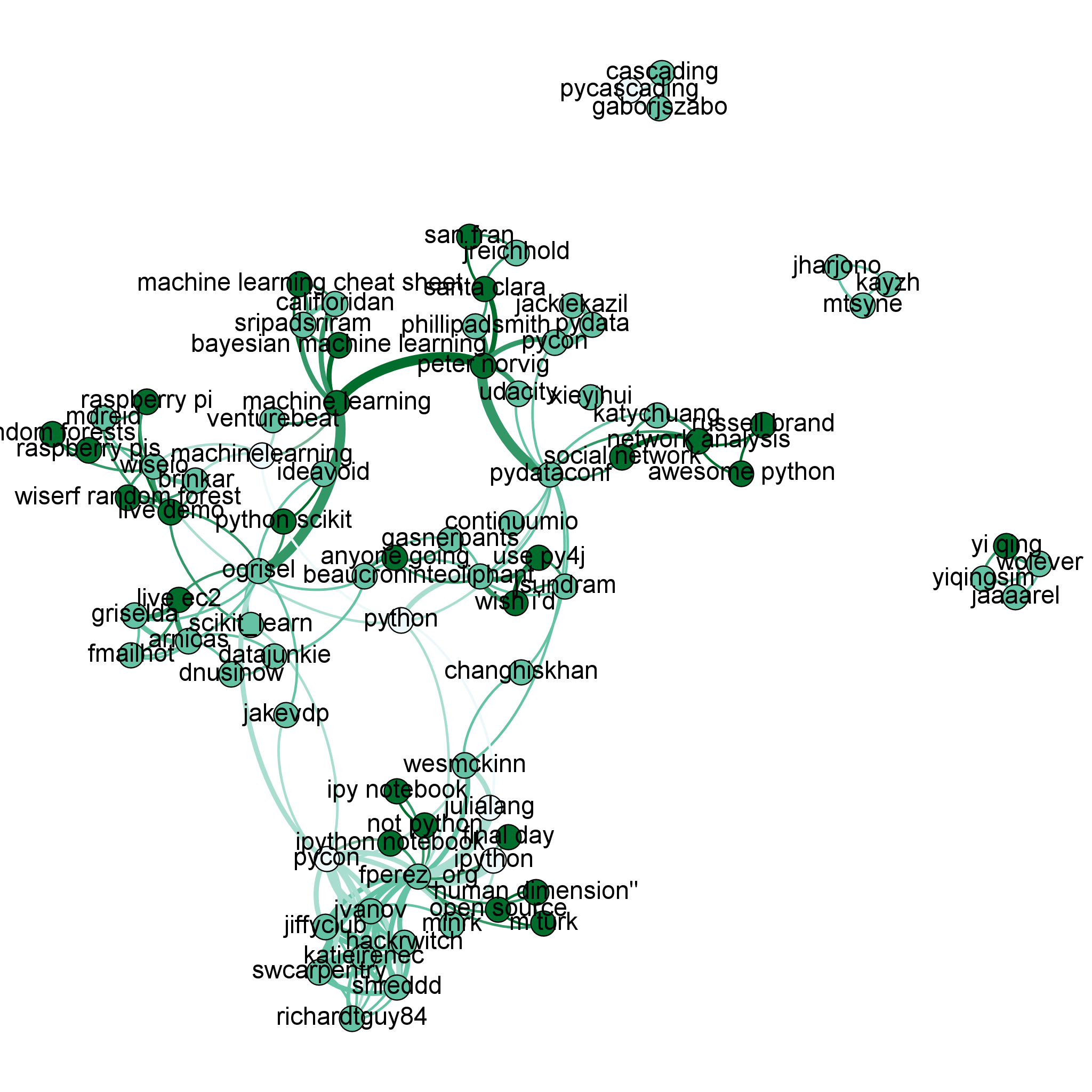
PyData 2013 is a much smaller conference than PyCon (PyCon had 2,500 people and 20% female attendance, PyData had around 400 with 10% female attendance). Being smaller it had far fewer tweets – after removing retweets I had just 225 tweets to analyse. Cripes! This is clearly not big data. The other problem was that people weren’t using many #hashtags, they were referring to topics using natural language. For example:
“Peter Norvig was giving a talk at PyData in Santa Clara, CA on the topic of innovation in education.” (source)
Clearly some natural language processing was required. I took two approaches:
- Extract capitalised sub-phrases (e.g. “Peter Norvig”, “Santa Clara”) of one or more words
- Use NLTK’s bigram collocation analyser (to find lowercased phrases such as “ipython notebook”, “machine learning”)
Starting at the bottom of the plot we see three types of colour:
- white is for #hashtags
- light blue is for @usernames
- dark green is for phrases (extracted using natural language processing)
We see a cluster of references around @fperez_org (Fernando Perez of IPython), one cluster is around @swcarpentry (the scientist-friendly software carpentry movement), the other is around IPython and the IPython Notebook (@minrk of IPython/parallel is linked too). I like the connection to Julia – Fernando discussed during his keynote that Julia now interoperates with Python.
The day before we had Peter Norvig (Director of research at Google) giving a keynote on the use of Python in education at Udacity including a discussion of how machine learning could be used to identify the mistakes that new coders make so we could make friendlier error messages to help students correct their code. See the clustering around this at the top of the graph.
Later the same day Henrik (@brinkar) spoke on Wise.io‘s Random Forest classifier. Their approach was efficient enough to demo live on a RaspberryPi. The connection from Peter to Henrik goes via #venturebeat who covered wise.io’s new software release during the conference.
Connecting IPython and Wise.io is @ogrisel (Olivier Grisel) of scikit-learn. He gave an impressive (and given the variability of conference wifi – slightly ballsy) live demo of scaling a machine learning system via IPython Parallel on EC2.
In the middle we see @teoliphant (Travis Oliphant) joined to Continuum (his company). Off to the right I get to blow my own trumpet – the phrases “awesome python” and “network analysis” connect to “russel brand” which is how one wag described my lightning talk. I got a chance to demo the earlier version of this at the end of @katychuang‘s talk on networkx.
London (geo-tagged tweets)

For the last month I’ve been grabbing tweets in the London geo area for another project. I had to raise my filtering levels to bring the network down to a sane (and easily visualised) number of nodes. After removing ReTweets I have 497,771 tweets from just a subset of my data. Some obvious clusters can be seen:
- #weather and #rain and (presumably a rather wet) “St Albans” (a very British discussion)
- The “O2 Arena” near the centre with “Justin Beiber” and #believetour, linked with #amazing, #excited, #nowplaying
- @onedirection must have been playing (connected with band members @louis_tomlinson and @real_liam_payne amongst others)
- To the top-right we have a football cluster with “Manchester United”, “Champions League”, #cpfc, #realmadrid and “Old Trafford”
- The usual tourist spots like “Tower Bridge”, “Covent Garden”, “Hyde Park”, “Big Ben”, “Trafalgar Square” are discussed with #happy #sun #loveit, linked just off of here is “London Heathrow Airport” and “New York”
Brighton (geo-tagged tweets)
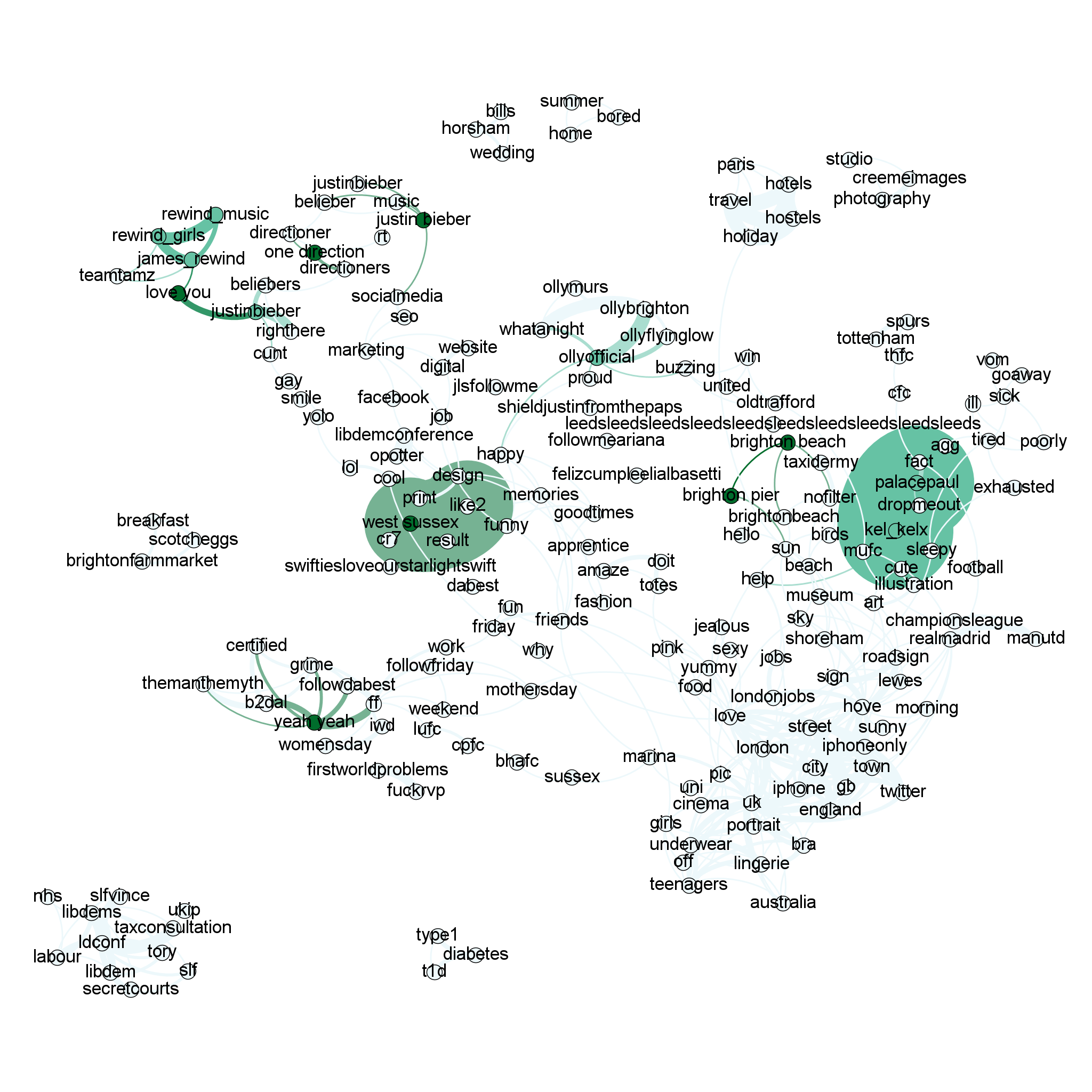
This is my favourite, analysed using 40,379 tweets after removing ReTweets. The nature of the two cities (Brighton is 50 miles south of London on the coast, it is a university town with a young & party-friendly population) is quite apparent:
- Top left there is discussion around “One Direction”, #justinbeiber and #seo (a particular Brighton tech thing)
- Just south of @justinbieber is a single chain of not-safe-for-work ranting (another particular Brighton thing)
- If you jump to the bottom right you’ll see #underwear, #lingerie, #teenagers – not as dodgy as you might expect, Sweetling were doing a social media bra campaign
- #hove is joined with #sunny #morning and nearby places #lewes #shoreham
- #brightonbeach and “Brighton Pier” connect with #birds (Seagulls – a bane!) and #sun
- #friends, #memories#, #happy, #goodtimes, #marina, #fun, #girls cluster around the centre (Brighton does like a party)
- Off down to the bottom left is a some sort of political discussion (what were they doing in Brighton?)
Reproducing this
All the code is in github at twitter_networkx_concept_map including the one line cURL command to capture the data. An example .gephi file is included for visualisation in Gephi. The built-in networkx viewer (optionally using GraphViz) works reasonably well but isn’t interactive. Maksim’s tutorial and utils class were jolly useful (utils is in my repo), I’m also using twitter-text-python for parsing @usernames, #hashtags and URLs from the tweets.
If you want some custom work around this, give me a shout via Mor Consulting.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
19 Comments