Maksim taught a lovely Social Graph Analytics course at PyCon the day before I taught Applied Parallel Computing. I took his demo for a “poor mans LDA/LSI analysis” of a Twitter topic (rather than using full LDA it just uses co-incident hashtags) and added usernames to produce the plot below.
Update – Analysing #pydata conference (and the cities London and Brighton) tweets using NLTK and NetworkX added as a second post.
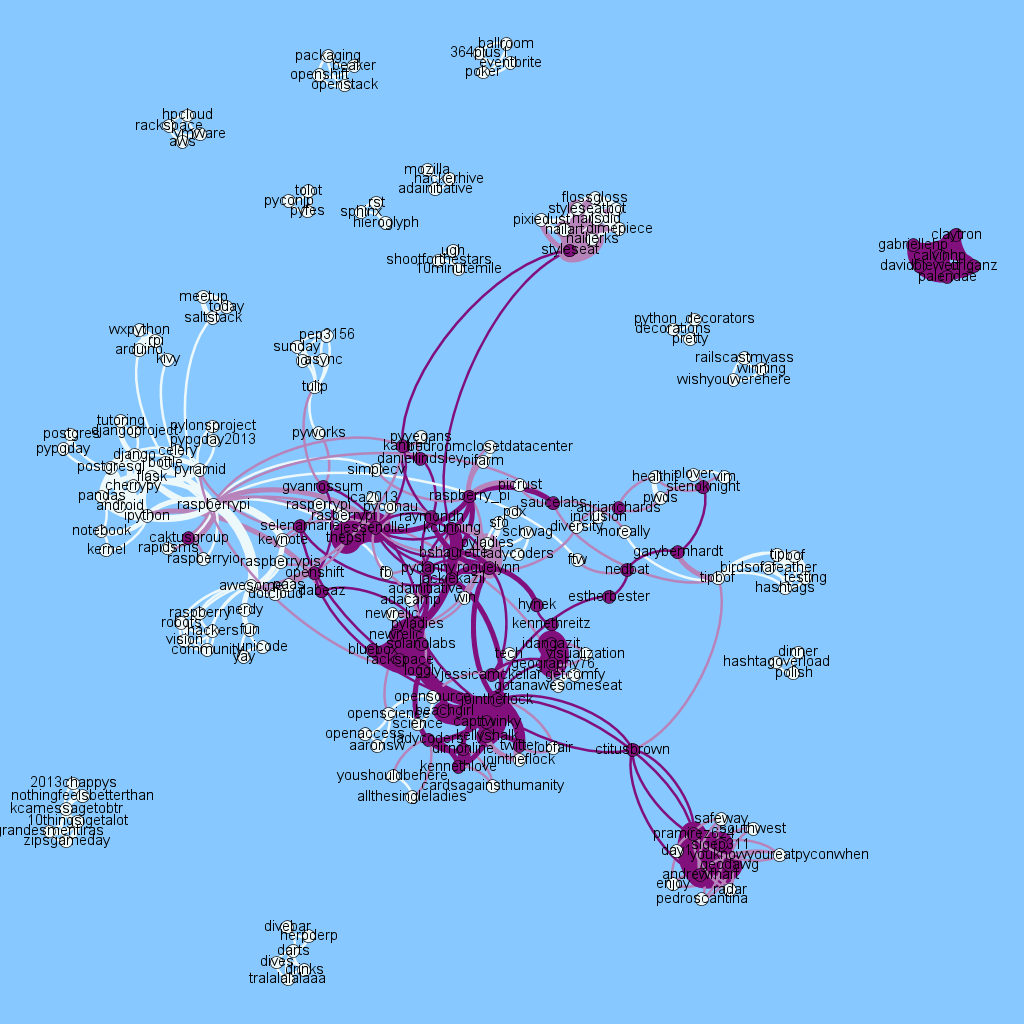
White nodes are hashtags (e.g. #raspberrypi centres the left white cluster), purple is for usernames (e.g. organiser @jessenoller is in the centre, Python’s creator @gvanrossum is between #raspberrypi and Jesse, @dabeaz and @raymondh are near the centre). We see a strongly connected cluster of people and hashtags along with several disconnected sets.
Over the course of PyCon I’ve collected all the #pycon tagged Tweets using the 1% Twitter Firehose (via a 1 line curl command). I have some Tweet parsing code which transforms this data into useful subsets (originally I was working on 2D geo-tagged plots of London and Brighton – to be posted later), in this case I extract the hashtags and usernames from each tweet using twitter-text-python and and then build edges in a graph for each pair of mentions that occur in a tweet. E.g.:
“really cool stenography talk by @stenoknight at #PyCon – she still uses #vim with #plover”
will cause a link to form between #pycon and #vim, #pycon and #plover, #vim and #plover. The width of edges in the diagram corresponds to the number of times the same hashtags (and users) are linked in each tweet. To understand which people are related to each concept I added usernames so in the above example edges are also formed between @stenoknight and the three hashtags.
If you open up a larger version of the image (click the main image) you can follow some of the detail. The #raspberrypi tag is interesting – lots of prominent projects are mentioned alongside (e.g. #pandas, #django). Just below the main cluster is a subcluster on #robots #vision #hackers – these are joined to the main #raspberrypi cluster by the adjective #awesome (rather lovely!). All 2,500 attendees of PyCon were given a full Raspberry Pi Model B during the Friday morning keynote by Eben Upton and during the weekend a RaspberryPi hacklab taught many people how to add hardware and use Python on the device.
In the centre we see a lot of people – many people mention each other or are linked by others (e.g. prominent speakers) in their tweets. I filter out ReTweets so we’re only looking at mentions of people inside one tweet if someone has written that tweet afresh. The legendary Testing in Python Birds of a Feather session (#tipbof) on the right is linked to a few prominent folk.
#openscience and #openaccess are well linked to the south of the main cluster, connected to the main group via clusters of people.
I’m quite intrigued by the @styleseat link out to #nailjerks #pixiedust #nailart to the north, they ran a manicure/pedicure session in connection with #pyladies.
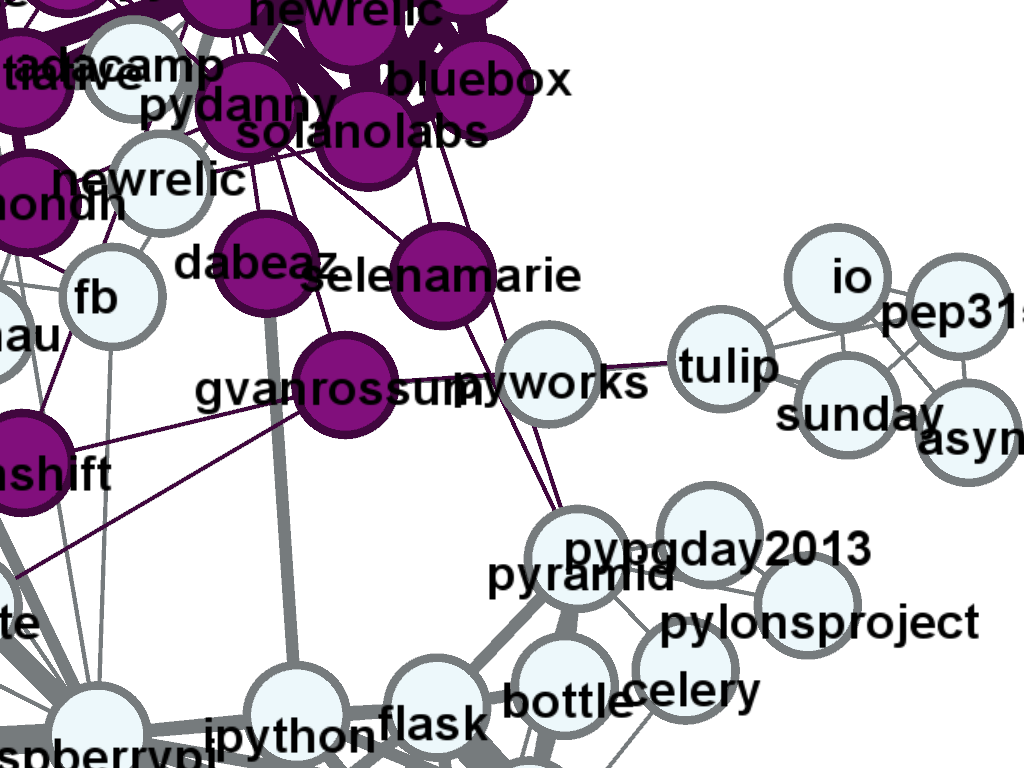
Guido gave a keynote this morning and discussed async programming – a new cluster formed (see zoom from earlier analysis shown above) from yesterday’s data with #tulip #sunday #pep3156 whilst talking about PEP 3156. It is interesting to note the time-based nature of the clusters (which we can’t see in this single 2D image, maybe I ought to animate it?).
Update I’ve added the plot below using the Community Detection feature of Gephi, it shows Guido’s async tag set as a separate cluster. #raspberrypi has a nicely large cluster, web servers have their own too.

Due to yesterday’s PyCon 5k Fun Run there’s a disconnected cluster for #10minutemile #shootforthestars #ugh to the north – 150 of us (of 2500 attendees) ran at 7am, we raised $7k towards cancer research.
It is worth mentioning that I removed some of the more prominent nodes as many of the other topics connect to these so they add little information:
- #pycon
- #python
- #pycon2013
- @pycon
- @top_webtech @inowgb (spammy)
- any username node with less than 50 occurrences
- any hashtag node with only 1 occurrence
I’ll add the code to github tomorrow. Tools used include twitter-text-python, networkx and Gephi. Update the code is in github as twitter_networx_concept_map.
If I get time whilst here I’ll do some more analysis on the data. I’d love to use a named entity tool or some parsing to extract obvious nouns (e.g. packages and topics) that aren’t #hashtagged.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
19 Comments