Our first few chapters of High Performance Python are nearly ready for the Early Release on O’Reilly’s platform, we’ll be releasing:
- Understanding Performance Python (an overview of the virtual machine and modern PC hardware)
- Profiling Python Code (for CPU and RAM profiling, lots of options)
- Pure Python (generators, the guts of dicts and the like)
We’ll announce the release via our mailing list, sign-up if you want to know as soon as it is available. Overall Micha and I have written half the book now (although this first Early Release will be just the first 3 chapters), we aim to finish the other half in the next few months.
The process of writing is very iterative…which means it is far too easy to write a bunch of stuff and then realise there’s a bunch of holes that need filling in (some of which turn into real rabbit-holes one call fall into for days!). Out the other side you get a nice narrative, lots of verified results and some nice explanatory plots. It just takes rather a long time to get there.
Here’s the first couple of pages of the start of the (just being written-up) multiprocessing chapter, I’m using a Monte Carlo Pi estimator to discuss performance characteristics of threads vs processes. Notice the black pen and scrawls to improves the diagrams – this happens a lot:

Right now I’ve been playing with Pi estimation using straight Python and numpy over many cores using both threads and processes (this chapter is just looking at multiprocessing, not JITs or compilers [that’s a later chapter]). Processes obviously provide a linear speed-up for this sort of problem, exploring the right number of processes and the right job sizes (especially for variable-time workloads) was fun.
Threads on numpy do something interesting – you can actually use multiple cores and so code can run faster (about 10% in this case compared to a single core), although they’re often not as efficient as using multiple processes. Here’s a plot of CPU use for 4 cores (and 4 HyperThreads) over time with threads. It turns out that the random number generation is GIL bound but the vectorised operations for Pi’s estimation aren’t: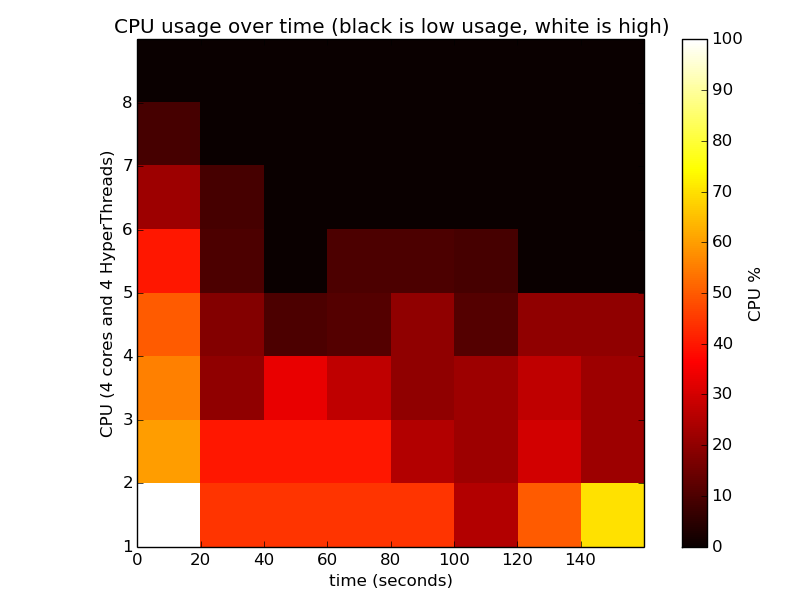
Join the mailing list for updates. Work on the book is supported via my London based Artificial Intelligence agency Mor Consulting.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
7 Comments