Below is a plot of Training versus Testing errors using a Precision metric (actually 1.0-precision, so lower is better) that shows how easy it is to over-fit a decision tree to the detriment of generalisation. It is important to check that a classifier isn’t overfitting to the training data such that it is just learning the training set, rather than generalising to the true patterns that make up the entire dataset. It will only be a good a good predictor on unseen data if it has generalised to the true patterns.
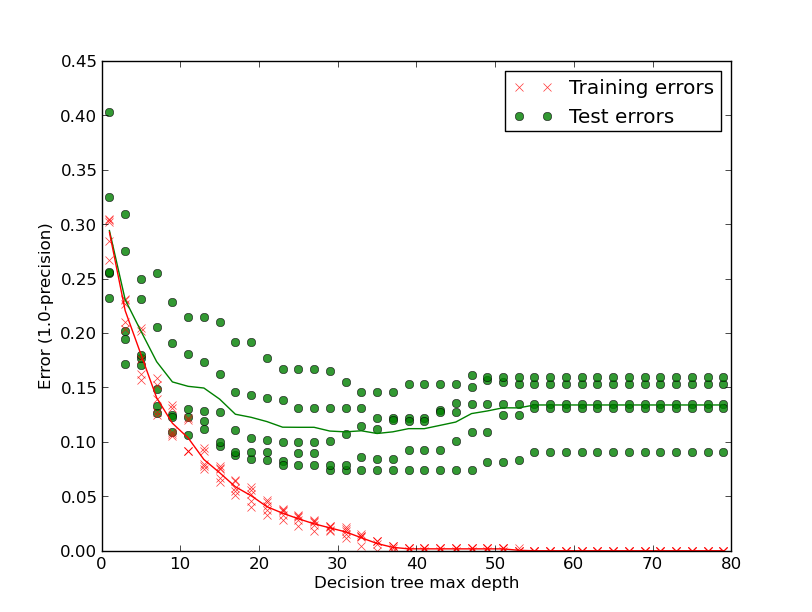
Looking at the first column (depth 1 decision tree) the training error (red) is around 0.29 (so the Precision is around 71%). If we look at the exported depth 1 decision tree (1 page pdf) we see that it picks out 1 feature (“http”) as the most informative feature to split the dataset (ignore the threshold, that’s held at a constant 0.5 as we only have 0 or 1 values in our training matrix). It has 935 samples in the dataset with 465 in class 0 (not-a-brand) and 470 in class 1 (is-the-brand).
The right sub-tree is chosen if the term “http” is seen in the tweet. In that case the the training set is left with 331 samples of which 95 are class 0 and 236 are class 1. 1.0/331*236 == 71%. If “http” isn’t seen then the left branch is taken where 234 class 1 samples are given a false negative labelling.
As we allow greater depth in the decision tree we see both the training and the testing error improves. By around depth 35 we have a very low training error and (roughly) the optimum testing error. By allowing the decision tree to add new branches it overfits, becoming a great predictor for the training set (the error goes to 0) but with worsening testing errors (the thin green line is the average – it increases past a depth of 35 layers). Decision trees tend to overfit due to their greedy nature.
I’ve added an example of a depth 50 (1 page pdf) decision tree if you’re curious. The social media disambiguator project has example code (learn1_biasvar.py) to generate this plot.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
4 Comments