Last week I had the pleasure of talking at both BrightonPython and DataScienceLondon to about 150 people in total (Robin East wrote-up the DataScience night). The updated code is in github.
The goal is to disambiguate the word-sense of a token (e.g. “Apple”) in a tweet as being either the-brand-I-care-about (in this case – Apple Inc.) or anything-else (e.g. apple sauce, Shabby Apple clothing, apple juice etc). This is related to named entity recognition, I’m exploring simple techniques for disambiguation. In both talks people asked if this could classify an arbitrary tweet as being “about Apple Inc or not” and whilst this is possible, for this project I’m restricting myself to the (achievable, I think) goal of robust disambiguation within the 1 month timeline I’ve set myself.
Below are the slides from the longer of the two talks at BrightonPython:
As noted in the slides for week 1 of the project I built a trivial LogisticRegression classifier using the default CountVectorizer, applied a threshold and tested the resulting model on a held-out validation set. Now I have a few more weeks to build on the project before returning to consulting work.
Currently I use a JSON file of tweets filtered on the term ‘apple’, obtained using the free streaming API from Twitter using cURL. I then annotate the tweets as being in-class (apple-the-brand) or out-of-class (any other use of the term “apple”). I used the Chromium Language Detector to filter non-English tweets and also discard English tweets that I can’t disambiguate for this data set. In total I annotated 2014 tweets. This set contains many duplicates (e.g. retweets) which I’ll probably thin out later, possibly they over-represent the real frequency of important tokens.
Next I built a validation set using 100 in- and 100 out-of-class tweets at random and created a separate test/train set with 584 tweets of each class (a balanced set from the two classes but ignoring the issue of duplicates due to retweets inside each class).
To convert the tweets into a dense matrix for learning I used the CountVectorizer with all the defaults (simple tokenizer [which is not great for tweets], minimum document frequency=1, unigrams only).
Using the simplest possible approach that could work – I trained a LogisticRegression classifier with all its defaults on the dense matrix of 1168 inputs. I then apply this classifier to the held-out validation set using a confidence threshold (>92% for in-class, anything less is assumed to be out-of-class). It classifies 51 of the 100 in-class examples as in-class and makes no errors (100% precision, 51% recall). This threshold was chosen arbitrarily on the validation set rather than deriving it from the test/train set (poor hackery on my part), but it satisfied me that this basic approach was learning something useful from this first data set.
The strong (but not generalised at all!) result for the very basic LogisticRegression classifier will be due to token artefacts in the time period I chose (March 13th 2013 around 7pm for the 2014 tweets). Extracting the top features from LogisticRegression shows that it is identifying terms like “Tim”, “Cook”, “CEO” as significant features (along with other features that you’d expect to see like “iphone” and “sauce” and “juice”) – this is due to their prevalence in this small dataset (in this set examples like this are very frequent). Once a larger dataset is used this advantage will disappear.
I’ve added some TODO items to the README, maybe someone wants to tinker with the code? Building an interface to the open source DBPediaSpotlight (based on WikiPedia data using e.g. this python wrapper) would be a great start for validating progress, along with building some naive classifiers (a capital-letter-detecting one and a more complex heuristic-based one, to use as controls against the machine learning approach).
Looking at the data 6% of the out-of-class examples are retweets and 20% of the in-class examples are retweets. I suspect that the repeated strings are distorting each class so I think they need to be thinned out so we just have one unique example of each tweet.
Counting the number of capital letters in-class and out-of-class might be useful, in this set a count of <5 capital letters per tweet suggests an out-of-class example:
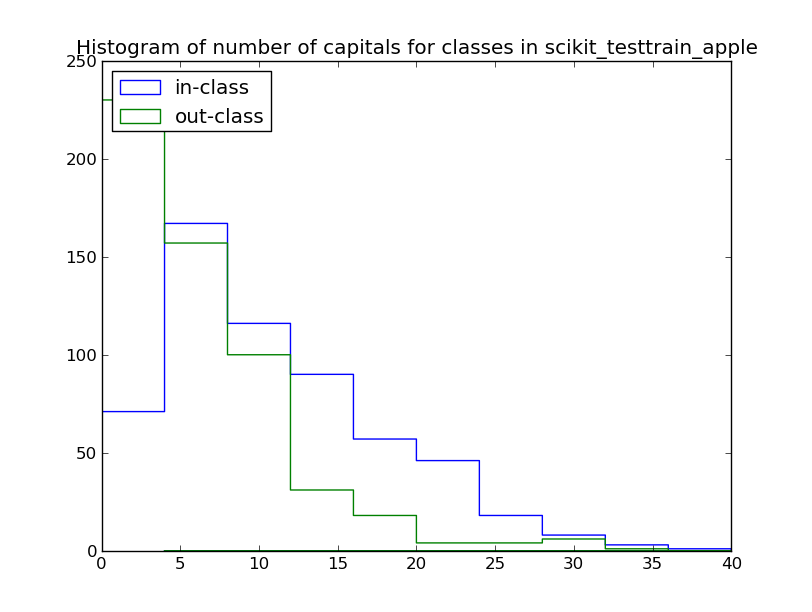
This histogram of tweet lengths for in-class and out-of-class tweets might also suggest that shorter tweets are more likely to be out-of-class (though the evidence is much weaker):
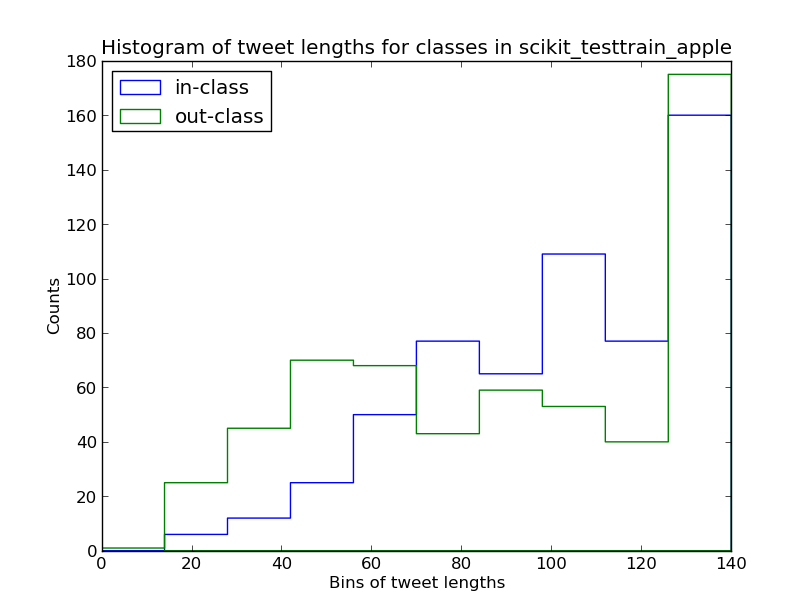
Next I need to:
- Update the docs so that a contributor can play with the code, this includes exporting a list of tweet-ids and class annotations so the data can be archived and recreated
- Spend some time looking at the most-important features (I want to properly understand the numbers so I know what is happening), I’ll probably also use a Decision Tree (and maybe RandomForests) to see what they identify (since they’re much easier to debug)
- Improve the tokenizer so that it respects some of the structure of tweets (preserving #hashtags and @users would be a start, along with URLs)
- Build a bigger data set that doesn’t exhibit the easily-fitted unigrams that appear in the current set
Longer term I’ve got a set of Homeland tweets (to disambiguate the TV show vs references to the US Department and various sayings related to the term) which I’d like to play with – I figure making some progress here opens the door to analysing media commentary in tweets.
Ian is a Chief Interim Data Scientist via his Mor Consulting. Sign-up for Data Science tutorials in London and to hear about his data science thoughts and jobs. He lives in London, is walked by his high energy Springer Spaniel and is a consumer of fine coffees.
2 Comments